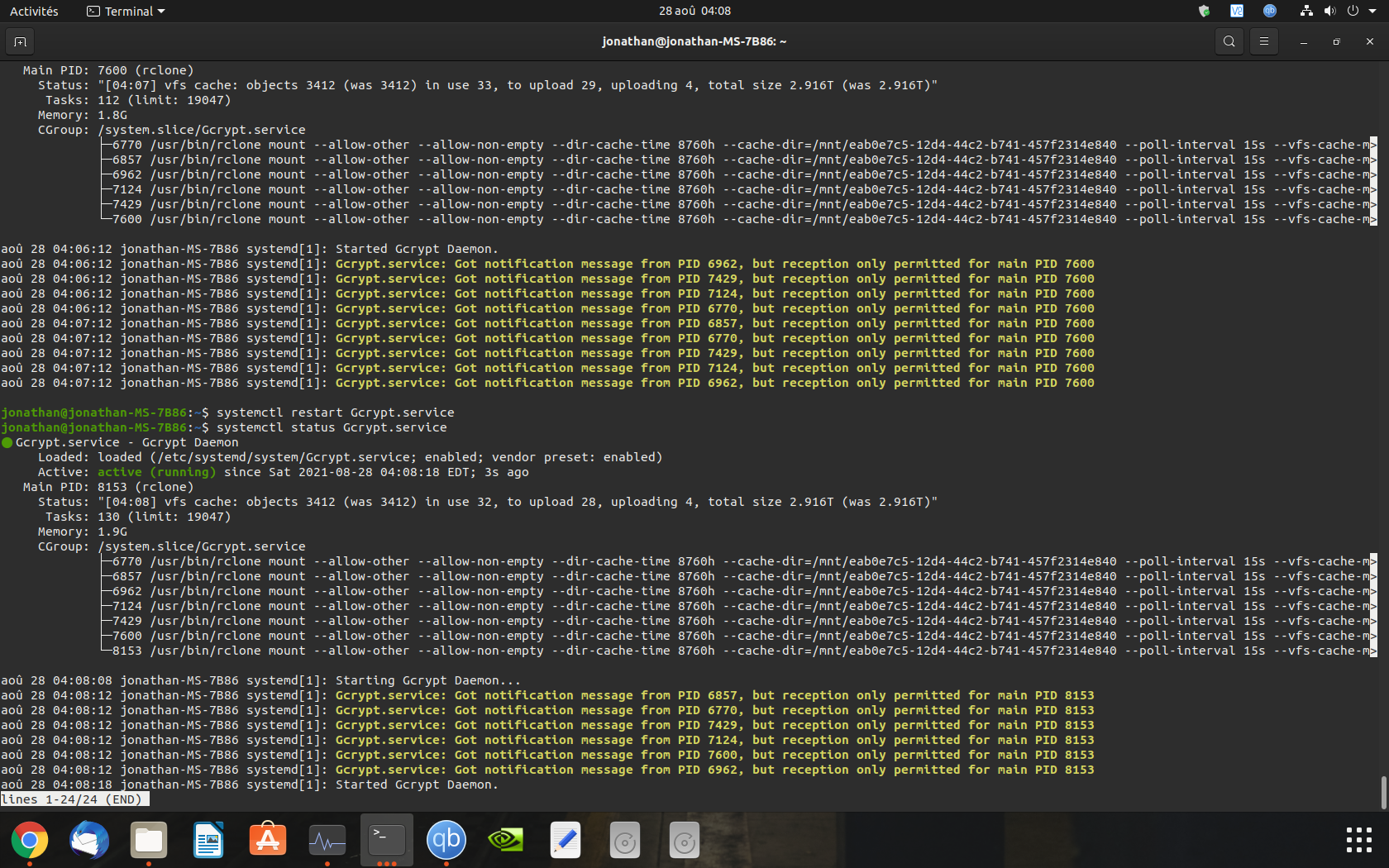
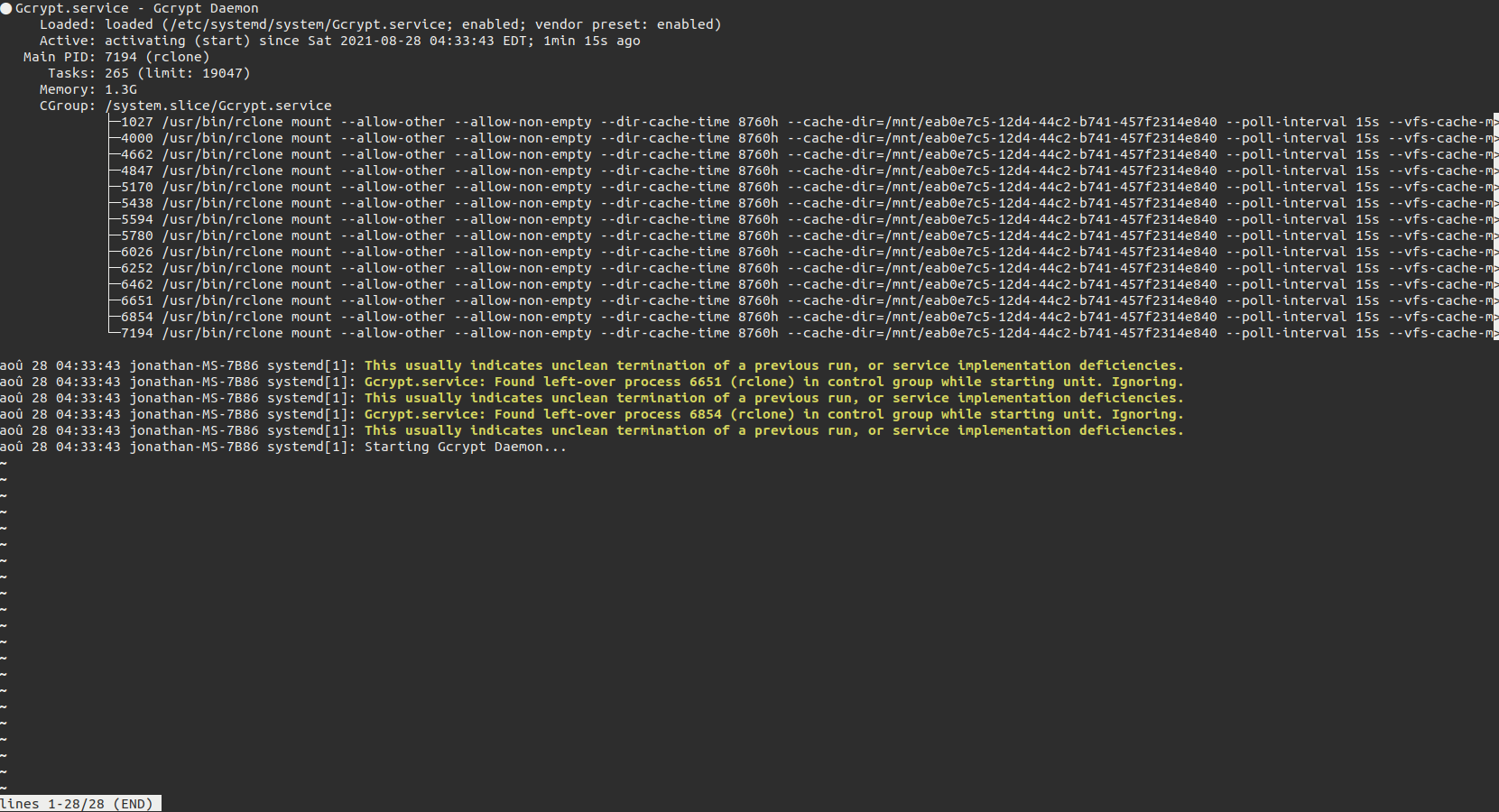
Hi! since yesterday I find myself with a funny problem. Rclone takes a long time to launch and during that time it uses all my bandwidth. Once started I notice that I finally have several rclone services running, yet I actually only have one.
What is your rclone version (output from rclone version)
rclone v1.55.0
os/type: linux
os/arch: amd64
go/version: go1.16.2
go/linking: static
go/tags: cmount
Which OS you are using and how many bits (eg Windows 7, 64 bit)
ubuntu 20.04
Which cloud storage system are you using? (eg Google Drive)
Google Drive
The command you were trying to run (eg rclone copy /tmp remote:tmp)
Paste command here
rclone mount --allow-other --allow-non-empty --dir-cache-time 8760h --cache-dir=/mnt/eab0e7c5-12d4-44c2-b741-457f2314e840 --poll-interval 15s --vfs-cache-mode full --vfs-cache-max-size 3000G --vfs-read-ahead 256M --vfs-cache-max-age 8760h Gcrypt: /mnt/cryption --user-agent="ams"
I don't know why it does this, but I did a test by disabling the service at startup.
systemctl disable Gcrypt.service
then I restart the server and start the service manually.
systemctl start Gcrypt.service
From there everything seems correct so I reactivated the
systemctl enable Gcrypt.service
service then I restarted. This is what I get
You need to add -vv to the startup and --log-file /tmp/rclone.log so we can get a log file as the systemd output doesn't give any information other than the service status.
The problem would come from the .service which cannot kill the rclone sessions when I modify them or restart them manually because of the killmode = none
I will try this instead
If you sigkill rclone, you get a mount point that won't function because IO is still stuck on it.
You want to stop all IO and have the proper require in your services so they stop and you can unmount the mount point with no IO/processing hitting it.
The purpose of that service file was to illustrate a 'required' line and nothing else.
My rclone service file is here:
I use KillMode=none as I don't want the OS killing it. I use required for all my services to ensure that no IO/processes are on the mount point and it unmounts.
It's not stupid I had precisely the "IO" problem in my opinion, because on occasion the server froze and resumed its activity 1 hour later or by forcing the restart.
Do you think --allow-non-empty could cause this problem?
I wouldn't say anything is stupid as each use case / situation tends to be unique.
It could, but I like to not guess and see log files as that leaves it for less debate.
I have all my settings documented based on my use and they work great for my setup.
I give some reasoning for changing each line so you can always adapt. If setting attr timeout fits for you, you can change. I advise to leave anything at a default unless I know why I'm changing it.