What is everyone's thoughts on how this new feature will impact Plex servers running on Rclone mounts.
Will it smash API or download limits by scanning entire libraries?
What is everyone's thoughts on how this new feature will impact Plex servers running on Rclone mounts.
Will it smash API or download limits by scanning entire libraries?
Noticed almost no issues with API usage from this being on last night as I was checking this morning.
It would somewhat depend on how your server is setup as well.
For me, it's pretty nice to have on as I think it's just a cool feature. I have everything local first so the default setting seems fine for me:

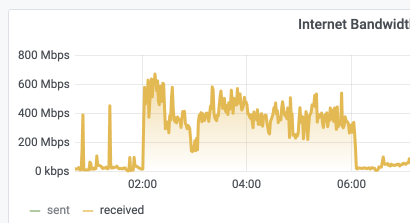
This does a scan on my local media when it's added and my normal schedule is for maintenance from 2am to 6am.
My traffic had a little bit of activity last night but not bad:
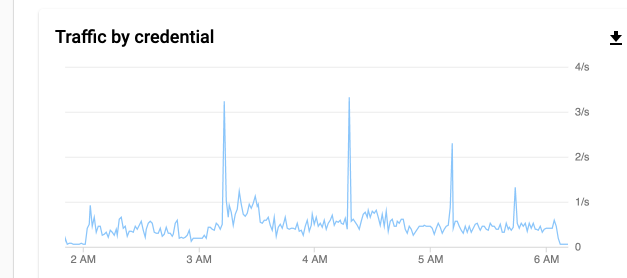
This was the night before so it does do some work in that period of time.
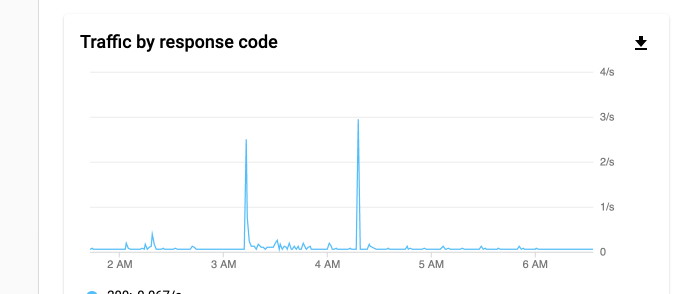
In that period though when it was doing things, it really didn't generate much API usage at all.
So for me, I'm going to leave it as is and go from there as it does not seem to worry me at all.
Did it scan old seasons that were not local? I had to kill it after it ran for 13 hours and only got half way through a single season. Thumbnail generation from rclone mount doesn't work so well for me either. I'm going to tweak my rclone mount settings and see if I can get it working better.
hi,
i disable thumbnail generation and set my mount to read only.
scans go quick that way.
Yes, it seems to work pretty well but would be dependent on your bandwidth as it does scan a good chunk of the file.
It does work, it just has to scan the whole file and would be somewhat dependent if you are using Plex or Emby and how you are storing the thumbnails. That means it has to download/read the entire file to generate thumbnails.
There shouldn't be too much tweaking per se as it's just reading the file. Mine ran for the entire maintenance window and do quite the work:
I changed my maintenance window to 23 hours (8AM to 7AM). I'm seeing BW utilization pretty consistent around 600mbps (I have gigabit). Checked the API metrics a couple of times and those didn't seem any higher than normal surprisingly. It's been running 17 hours and seems to have made it through ~100 seasons. Viewing your TV library by episodes, sorted by date added seems to be the order it is taking. (Most recently added to oldest). When it hits an episode for a season it hasn't analyzed it scans that whole season, I would imagine when it hits another episode from that season it would skip past it. As new stuff comes in it seems to run a simultaneous scan on that new episode/season.
I doubt there's a way to speed this up, I hope that soon someone much smarter then myself creates a script/utility that can check and report back on the number of episodes/seasons with/without intro data so I can get a better idea of how it's progressing.
It is documented here for anyone looking:
It some caveats associated with it.
From what I can surmise from reading posts and the support article, I believe it only checks the first 10 minutes of an episode with its algorithm to find the intro which is much different than deep analysis or thumbnails which hit the whole episode.
The default setting is to analyze the new media when it is added and to run the scanner task for old stuff during the maintenance window.
This feels like one of those things though once it's caught up, it really becomes a non problem. I think the challenge here is the first days when the old library catches up.
It is a pretty cool feature I must admit as I was taken back by how well it does work.
It's an undoubtedly cool feature and it works exactly as it should when I tested it on a show I manual scanned last night. Yea once it's caught up it shouldn't be a problem, but I've made it through ~100/3600 seasons in nearly 24 hours of scanning on a gigabit connection. Some people may not be willing to have a 23 hour maintenance window while it tries to catch up and also may not have as much bandwidth, so the time it takes for everyone's servers to make it through the backlog is going to vary widely, which is why I was hoping for a way to check actual progress.
I've pieced through you can check the XML for the a show and see if it exists, but that doesn't quite tell if it was processed or not. I was trying to figure out the same thing.
I've tried to not use the task and manually analyze a season, but that does not seem to work for me.
Yea I've noticed it adds to the XML below the "chapters" with an "intro" segment. Oddly I found that by looking at a season I manually analyzed compared to the shows next season which I had not.
Do you know if these "chapters" are stored in the Plex DB anywhere? Might be easier to pull the data through that.
Removed "buffer-size 32M" and instead using "vfs-read-chunk-size 32M" and have now been able to get it to analyze a couple seasons successfully.
Now that I have some episodes with and without "Markers" that have been analyzed, it should be possible to figure out how that's stored in the database.
You'll need the library_section_id for these.
How many have been analyzed for intros:
select count(*) from media_parts mp join media_items mi on mi.id = mp.media_item_id where mi.library_section_id = 8 and mp.extra_data like '%intros=%';
How many have not been analyzed for intros:
select count(*) from media_parts mp join media_items mi on mi.id = mp.media_item_id where mi.library_section_id = 8 and mp.extra_data not like '%intros=%';
How many actually have intros:
select count(*) from media_parts mp join media_items mi on mi.id = mp.media_item_id where mi.library_section_id = 8 and mp.extra_data like '%intros=%%7B%';
Files with intros:
select mp.file from media_parts mp join media_items mi on mi.id = mp.media_item_id where mi.library_section_id = 8 and mp.extra_data like '%intros=%%7B%';
I'm sure someone can put together a nice script to format some nice output.
I use a modified version of @Ajki's library stats so I just added those few queries to that and modified as my library section is 2:
is my file those are the last lines of the output.
701 analyzed for intros
36562 not analyzed for intros
223 have intros
Thank you, will have to try this out in a few.
This is where I'm at in a little over 24 hours, so average low at 2,000 episodes per day it'll take about a month
2344 analyzed for intros
51698 not analyzed for intros
836 have intros
The Plex scheduled task is still getting hung up. It will get through a few episodes and then seems to get stuck. I have to reboot to get it cleared.
I can actually play media from the rclone mount, but analyzing for intros and generating thumbnails both seem problematic. Both of those use the Plex Transcoder. But I've also noticed some remote users playing content from the mount that is being transcoded and that also seems fine.
Any advice to help diagnose?
Why do you think it's getting stuck? Can you share something that would show that?
At around 10 AM this morning I noticed Plex was scanning for intros. I checked and the current episode's Plex Transcoder process had started at 2:08 AM. It did seem to get through 4-5 episodes before that.
My setup is similar to yours with mergerfs and rclone mount. My rclone mount settings are pretty much the exact same that you have in your homescripts github repo.
I had the scan running 23 hours per day all weekend and woke up today to 403 download limit exceeded errors. I stopped the scanning process move. Stopped all the rclone mounts for a couple of hours, created a new client ID and started everything back up and am still getting the downloadquotaexceeded errors. Assuming a 24 hour ban. Google page states that daily quotas reset at midnight PST so if I'm still up then I may try starting everything back up and see if I can play any media without letting the intro scan start back up. If not hopefully tomorrow afternoon everything will start working again.
I took a different approach and just let it run for a 8 hour period each night and it'll finish when it gets done as any new media is already taken care of.
Did you actually download the 10TB in the day?