I've been lurking here for a while and I see the same repeated misconceptions, so I want to give some clarification and correction on downloadQuotaExceeded.
VFS-Read-Chunk causes rclone to download the file in pieces, which means several drive.files.get calls, which in turn means that the file is downloaded each chunk. If you look at admin.google.com and go to reports > drive, you'll see "User downloaded XXXXXX.yyy" several times in a row. This adds to the UNPUBLISHED file download quota! You have 1 billion API calls a day, but that doesn't mean you can download 1 billion times a day. API quota != download file quota.
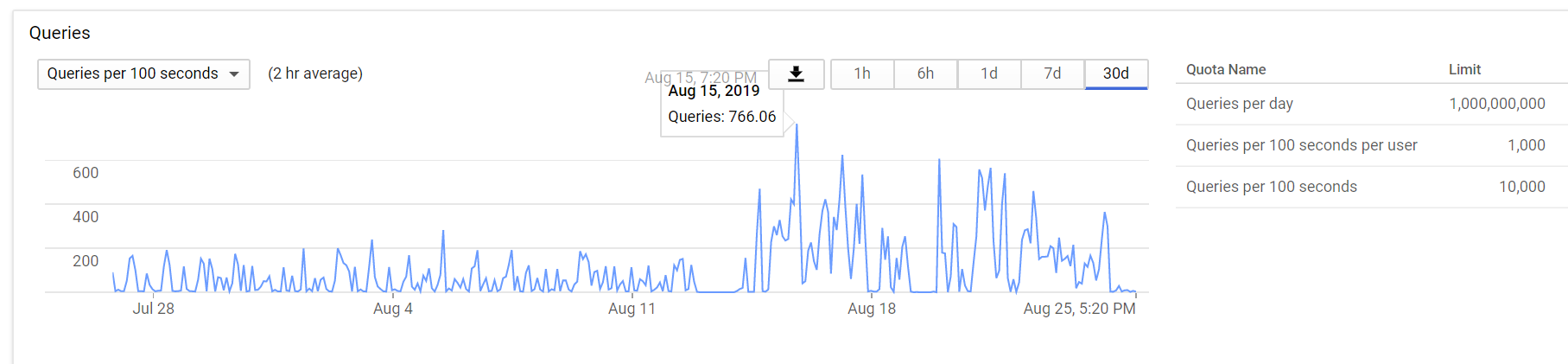
Lately, I've been hitting file download quota exceeded a lot lately, almost daily for the past 2 weeks.
I believe google lowered the download quotas. in part because of abuse, unfortunately rclone is a problem. That would explain why google rate-limited rclone a few months ago. rclone "downloads" the file several times during playback.
The VFS system needs a way to only download the file once, so it's only 1 download counted against the quota, not the 10-50 times I see reported in the audit reports. VFS-Cache-Mode-Full downloads the file at least twice, and has problems playing with plex. I use mergerfs, maybe I need to add my /cache/vfs/drivename to the pool?
You may not run into this issue yet, I certainly didn't for almost a year. Now my library is over 180TB and the 12 hour scans of sonarr and radarr cause the files to be downloaded multiple times as well (I have analyze videos on, never had this issue until this month).
To stop unnecessary scanning and mediainfo downloads:
- Turn off plex automatic and daily scans, keep partial scan on, use sonarr/radarr connect feature to notify plex (I had this set for a long time now)
What I did last week:
- Upgrade to Sonarr V3 and Radarr V2 (new UIs). They include a new setting under media management (advanced settings) to disable disk scans when refreshing series. I set it to "only on manual refresh". So now when sonarr/radarr refreshes the series, it won't rescan all the files.
As long as plex and sonarr/radarr are up and setup appropriately, nothing should get out of sync where you need to manually scan.
This has reduced the overall files downloaded every day, but has not resolved the file download quota bans.
After initial scans, it doesn't make much sense to have a --vfs-read-chunk-size lower than 64M, 128 is a good middle ground to 256M. The lower vfs-read-chunk-size, the more drive.files.get = the more download file calls. Remember, the number of API calls is not the problem, instead it's the type of api call. vfs-read-chunk-size calls drive.files.get several times to get the chunks. Each call = 1 file download. The limit may be 100 per 24h, but it's unpublished, it could even be 50.
Unfortunately, I'm still running into the download quota exceeded ban. Other misconceptions about this ban:
- it has nothing to do with overall api calls, or 100 calls per limit, tpslimit, etc.
- In most cases, it's not the 10tb download daily limit.
- It's a separate unpublished limit per file. There also seems to be another quota, total max downloads allowed per day.
- It's directly related to how many times a file is downloaded. VFS read chunk size = 1 download call. So 128M = 1 download, the next chunk is another download, etc. As the file is played and more chunks are downloaded, those are each 1 download to google. You can verify this in your admin drive audit report.
It seems vfs-cache-mode=full does not prevent multiple file downloads. In my experience it sends up stalling plex for a few minutes instead, even after the file is downloaded and in my /cache directory within 2 seconds of starting playback. I plan on testing playback if I put the /cache/vfs/tdrive directory in my mergerfs.
For reference here is my rclone setup: Yes I know some of these are repeating defaults, I keep them here for easy tweaking and testing. I typically remove the vfs-read-chunk vars if I setvfs-cache-mode=full
[Unit]
Description=tdrive.service
Wants=network-online.target
After=network-online.target
[Service]
Environment=RCLONE_CONFIG=/opt/rclone/rclone.conf
Type=notify
ExecStart=/usr/bin/rclone mount tdrive: /mnt/tdrive/remote \
--config="/opt/rclone/rclone.conf" \
--log-file="/opt/rclone/logs/mount.log" \
--user-agent="myagent/v1" \
--dir-cache-time="72h" \
--drive-chunk-size="128M" \ # this does have an affect is vfs-cache-mode>= writes, see replies below
--vfs-read-chunk-size="128M" \
--vfs-read-chunk-size-limit="off" \ # if you don't specify this, then it will just do 128M chunks, which would be really bad as it would be more file downloads.
--vfs-cache-mode="off" \ # I also tested with full, in doing that the read-chunk settings should be ignored, currently i have this on full.
--vfs-cache-max-age="72h" \
--cache-dir="/cache" \
--buffer-size="0" \ # the buffer seems to cause buffering issues on a fast 1gpbs connection, didn't notice a difference when the buffer-size, except with 0. Buffer 0 is recommended when using vfs-cache-mode=full
--log-level="NOTICE" \
--allow-other \
--fast-list \ # The docs say it affects stuff like ls calls, which a mount does. See replies below for more info.
--drive-skip-gdocs \
--timeout=1h \
--tpslimit=8
ExecStop=/bin/fusermount -u "/mnt/tdrive/remote" # for some reason this fails for me on systemctl restart, but calling it manually (without sudo) works fine...
Restart=on-failure
User=1000
Group=1000
[Install]
WantedBy=multi-user.target
[Unit]
Description=mnt-tdrive-merged.mount
After=tdrive.service
RequiresMountsFor=/mnt/tdrive/local,/mnt/tdrive/remote
[Mount]
What=/mnt/tdrive/local=RW:/mnt/tdrive/remote=NC
Where=/mnt/tdrive/merged
Type=fuse.mergerfs
Options=async_read=false,use_ino,allow_other,category.action=all,category.create=ff,func.getattr=newest
[Install]
WantedBy=multi-user.target
/mnt/tdrive/remote #rclone mount
/mnt/tdrive/local # where local files will be stored until upload, matches dir structure of remote
/mnt/tdrive/merged # the merged view that plex uses.
So I have 2 issues, downloadquotaexceeded because of vfs-read-chunks
vfs-cache-mode=full stalling plex, takes minutes and stopping/playing for it to play. It ends up downloading the file 4 times, probably analyzing and downloaded the entire file 4 times.
Even after file is in the cache, plex playback is stalled.
I'm going to try to put /cache/vfs/tdrive into the mergerfs pool after the local drive and make that RO, just to see if that makes a difference for plex.
It honestly seems like the vfs mode needs some work.
It needs to detect when a file is already in the process of being downloaded and re-use that instead of making a 2nd download call.
Ideally, google api permitting, it needs a better way to do the read chunks so it's just a single file download call, but still read in chunks. Gdrive website and gfs is able to do this....
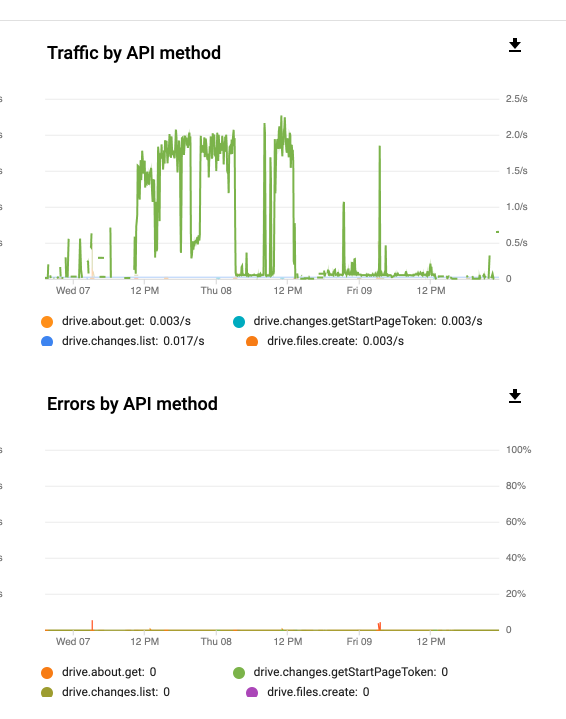
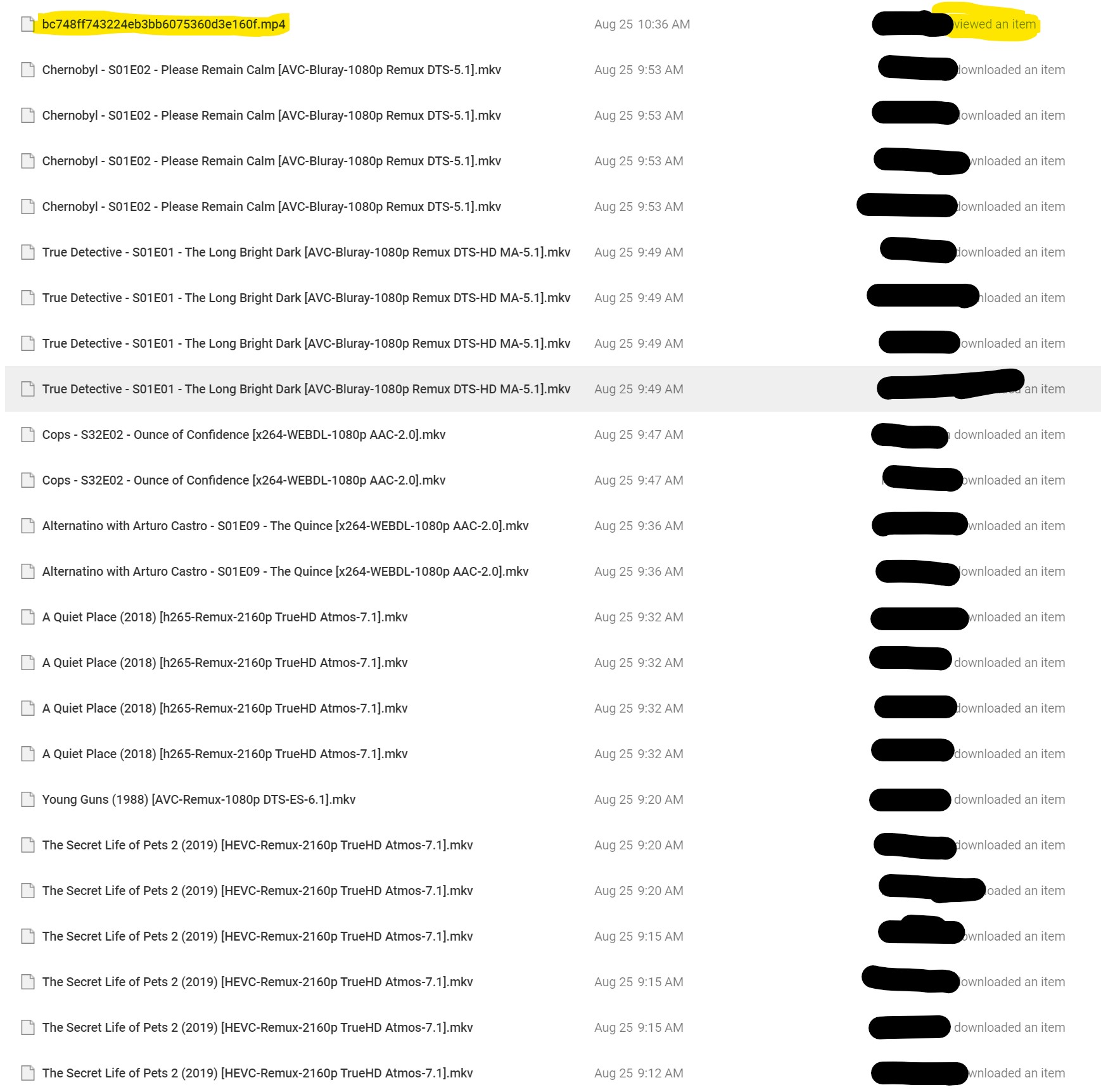
Here is a part of my audit log:
The highlighted item is a video i viewed and seeked a few times on the gdrive website. Notice how it says viewed item and the rclone ones say download.
Notice how Chernobyl was downloaded 4 times. I have vfs-cache-mode=full on, it still made 4 download calls at the same time. VFS-Cache-Mode=Full was tested on everything after secret life of pets 2. All of the files listed, playback was started once and stopped once it started playing. Secret life of pets 2 has vfs-cache-mode=off. 9:12am and 9:20am were different playbacks.
Secret life of pets was worse, more download calls during playback with cache mode off.
I may try testing the rclone cache wrapper to see if this solves the multiple downloads.
It seems from the audit log, cops and alternatino only downloaded twice. True Detective 4 downloads with cache-mode-full. I'm guessing file analysis needed to run on that file.
Chernoybl is being played with transcoding, so far still the original 4 downloads in the audit log and nothing else yet.
So it seems vfs-cache needs some work to capture consecutive reads on the same file.
There needs to be a stream cache mode,
vfs-cache-mode=stream. It will cache chunks as they are downloaded, not waiting for the entire file to be downloaded first.
Is there possibly a better way to do streams in the api? GDrive website seems to "view" a file when playing a video on the site (their transcode of it?). Seeking around doesn't cause additional entries in the audit log.
BTW using latest beta with the cache-fix:
rclone v1.48.0-227-g077b4532-beta
- os/arch: linux/amd64
- go version: go1.12.9