Yes, every transaction would be part of the overall limit.
this is quite straightforward :
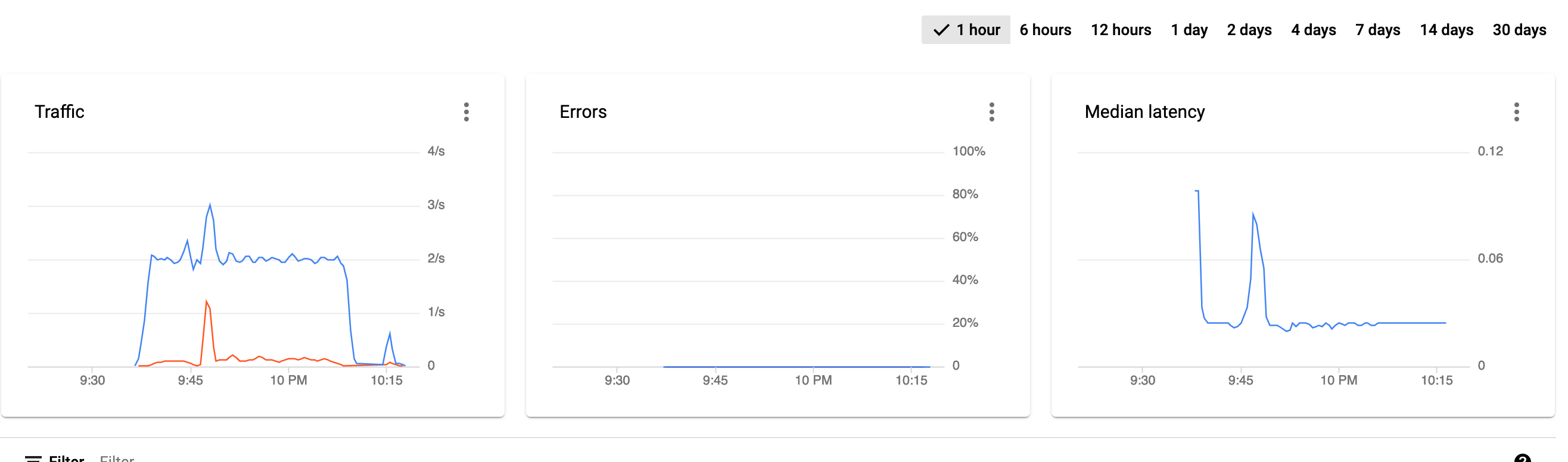
tpslimit = 3 -> absolutely NO 403's.
But we clearly can see I started the transfer, and that it suddenly drops to barely no bandwidth at all.
I will try to roll back to a previous version of rclone and see if this could be the problem. This started after latest update (1.59)
So 1/2/3 work but when you go to 4, you get 403s? Please just ignore the speed part as that's a separate issue.
4 also no 403s...
I basically run a transfer, put -vv in a log and "cat log.txt | grep "403"" it.
the API graphs shows no error happened
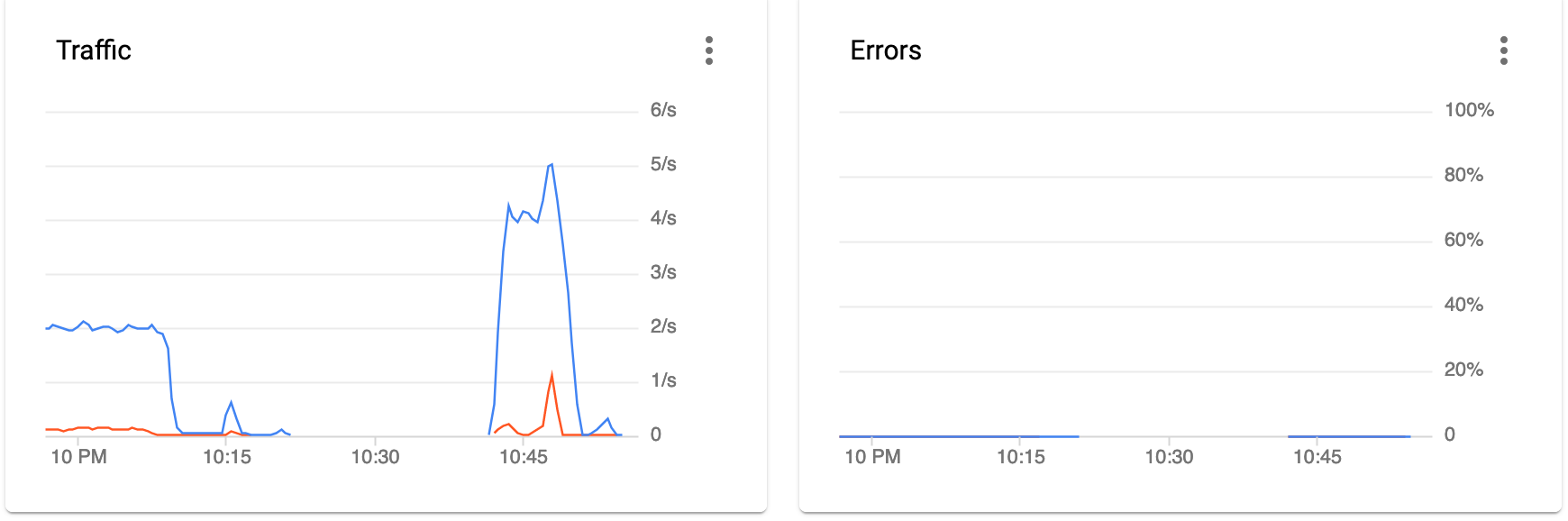
but lets face it, as you can see in the above screenshot, the second test I made (tpslimit 4) shows no 403 which is fine, but rclone is totally useless now, I can't transfer any files for more than XX minutes to my local storage. So bandwidith definitely is an issue.
I think you are misunderstanding me.
We have two problems to solve here and you can't fix both at the same time. I shared another threads with weeks of information on slowness with Google and ways to get around that.
If you want to solve the 403 issue, we need to step through it methodically to figure it out. If you'd like to continue with the 403 issue, step up the TPS and see where it breaks. Once you have a breaking point, validate that with a few different versions and see if perhaps a regression came up causing an issue.
I've see no other reports of rate limits from anyone so that feels unlikely, but your specific situation/use might be unique.
We won't know anything for sure unless we take a pragmatic approach to fix it. If you want to fix it fast, I'm not your guy. If you want to get to the root cause, we need to step through it slowly knowing what we change and where it breaks.
You need to make the call here as it's your time as well and decide how important it is for you to figure out as I can only offer my thought process as I don't use Google Drive and I get paid the exact same if you work or don't work (that's my attempt at humor).
haha yeah, well, I will have to keep testing tomorrow, it's getting quite late over here ![]()
See you tomorow @Animosity022 and thanks again for the great support.
I'll figure out the breaking point + will downgrade to see if going back to 1.5!.1 fixes something. Stay tuned.
on more test run overnight, I started a transfer I've left running for approx 9 hours :

As usual, it started OK.
tpslimit = 4
I've finally got two 403's at 8am. But nothing significant really.
the graphs:
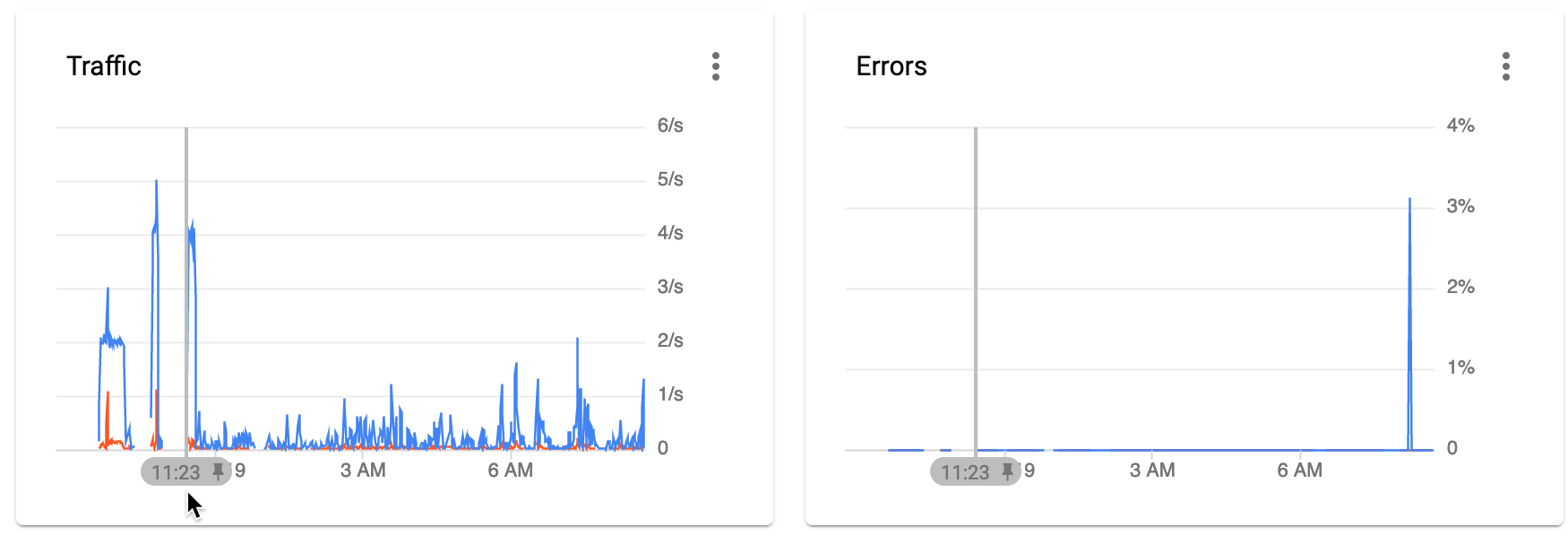
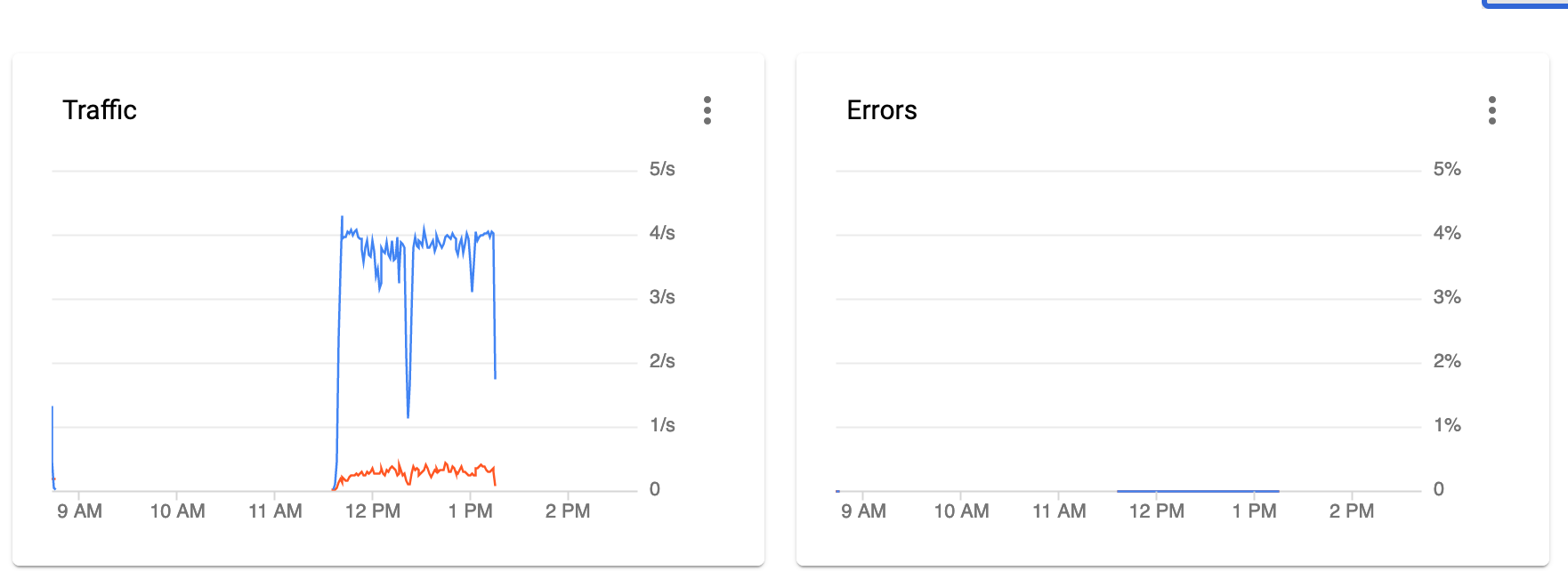
here we see the copy started at approx 11.23pm
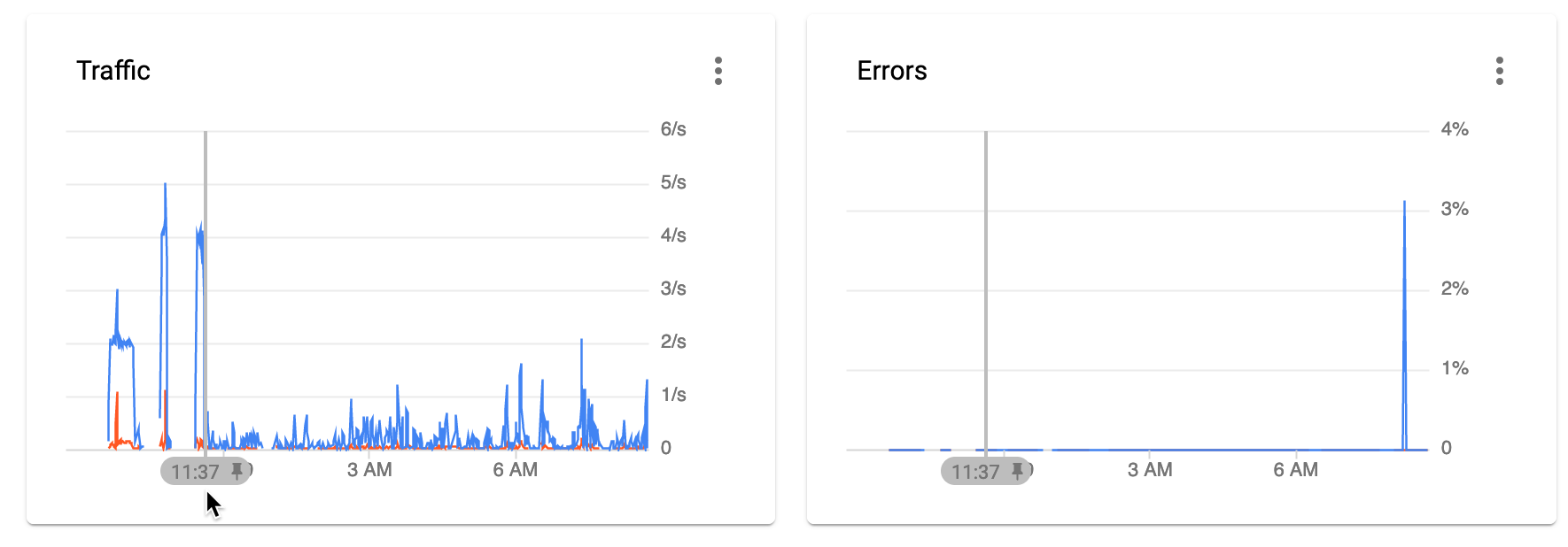
And the drop happened around 11.37pm
I did use a manually installed rclone 1.58 to run this test, so it is unfortunately not related to update 1.59.
We also can see that tpslimit finally get triggerred when using tpslimit 4
Hmm, at that point, I'm not quite sure as it's seems an account problem. Perhaps trying a support call to see if they can give some details might help.
@ncw - any other thoughts? Seeing the OP hit an issue with 403s with a tpslimit of 4 with the quotas being so high makes no sense to me. If rclone itself was misbehaving, I think more people would be chiming in.
This does look like google doing rate limiting - but maybe it is on the bandwidth? I see you got 45MiB/s for a long time and then it dropped down to 7MiB/s or so. I wonder if this is a new kind of rate limit based on continuously transferred data or something like that?
Maybe try experimenting with --bwlimit so to keep the bandwidth usage to --bwlimit 20M say for 20MiB/s maximum?
This is exactly what I did think as well. As I've never had any issues in the past, got the new server at home, and suddenly started to download a "high" amount ot cloud stored data locally, I ask myself if it is not google that caps me.
Just to be sure about this, I did run the exact same transfer on a server I do rent in a DC in Amsterdam.
The setup there is rclone 1.52, and a 1gbit line.
I ran the exact same copy to to local hard drive of my server, and was able to copy almost 400gb in about 1h30, with NO DROPS.

So what remains on my test bench list :
- run the same transfer, but from a different server at home (to see if my unraid server might be the problem, eventually limiting the transfer rate when it do reach a specific disk of the array)
- if my other server has the same issue, bring it to the office, and see if the same exact transfer get capped from there (to see if my IP could have been capped by google, or even my internet provider?)
It is a pretty weird issue indeed, but now I do know it DO work fine from another server/location. So I'm close to see if this issue comes from either my server / either google/ISP cap.
I'll keep you posted !

Got the same problem you do, right after moving to unraid, so i'm guessing its related
Hi Daniel,
Just for the sake of testing here is what I did.
I moved my HBA pcie card from the 4x slot it was plugged to, into a 16x one, and it suddenly started working fine again. I transferred about 7Tb of data with no more drops, and guessed my problem was related to the usage of that 4x port.
Yesterday night, I've got several power outages, and my UPS did its job keeping my unraid server powered. But when I woke up, I noticed the transfers did again drop to a few kbit per second.
I did stop the transfer, restarted the server, and one more time, I've got 45MB/s speeds for a few minutes, then again, a drop.
So what happened ? Well, my server kept running, but obviously, it lost its connection to the internet for a while. this is all I can see. And this literally caused this issue, as my previous transfer ran for 47 hours without any drop !
So what did I do in the meanwhile that fixed the transfer times for a while ? I replaced a disk, ad rebuilt the data therefore... I have no clue what that means, but I guess unraid somehow can't communicate the right way with rclone at some point. For whatever reason.
One other thing I did notice, is that, when the drop happens, the 45MB/s'ish transfer rate freezes in the rclone cli progress status text. It is not updated dynamically anymore. If anyone here has an idea of what could cause this, we might have a path to follow to investigate this issue.
the below screenshot shows that rclone thinks it is transferring at 40+MB/s still, while you can see only 16gigs were transferred in more than an hour

So, yes, something bad is happening with unraid, and I'm happy to discuss this more in detail with you on the official unraid discord server if you want to join.
Well, I wanted to come here and share what the final outcome of this whole story is.
I detected that the drops did happen ONLY when writing two specific disks of my array.
It ended up that these two disks are SMR drives. And SMR disks are known to drop when multiple small files are written to them. This is due to the cache filling, till its full, then the drop happens.
I removed the two drives from the array... no more issues.
What does that mean ? Three things:
- rclone is not the bad guy here
- Neither is Unraid
- KEEP AWAY FROM SMR hard drives !!!
some litterature :
once again, thanks for the help you provided guys !
Thanks for the explanation. I didn't know about SMR drives before! I will avoid I think...