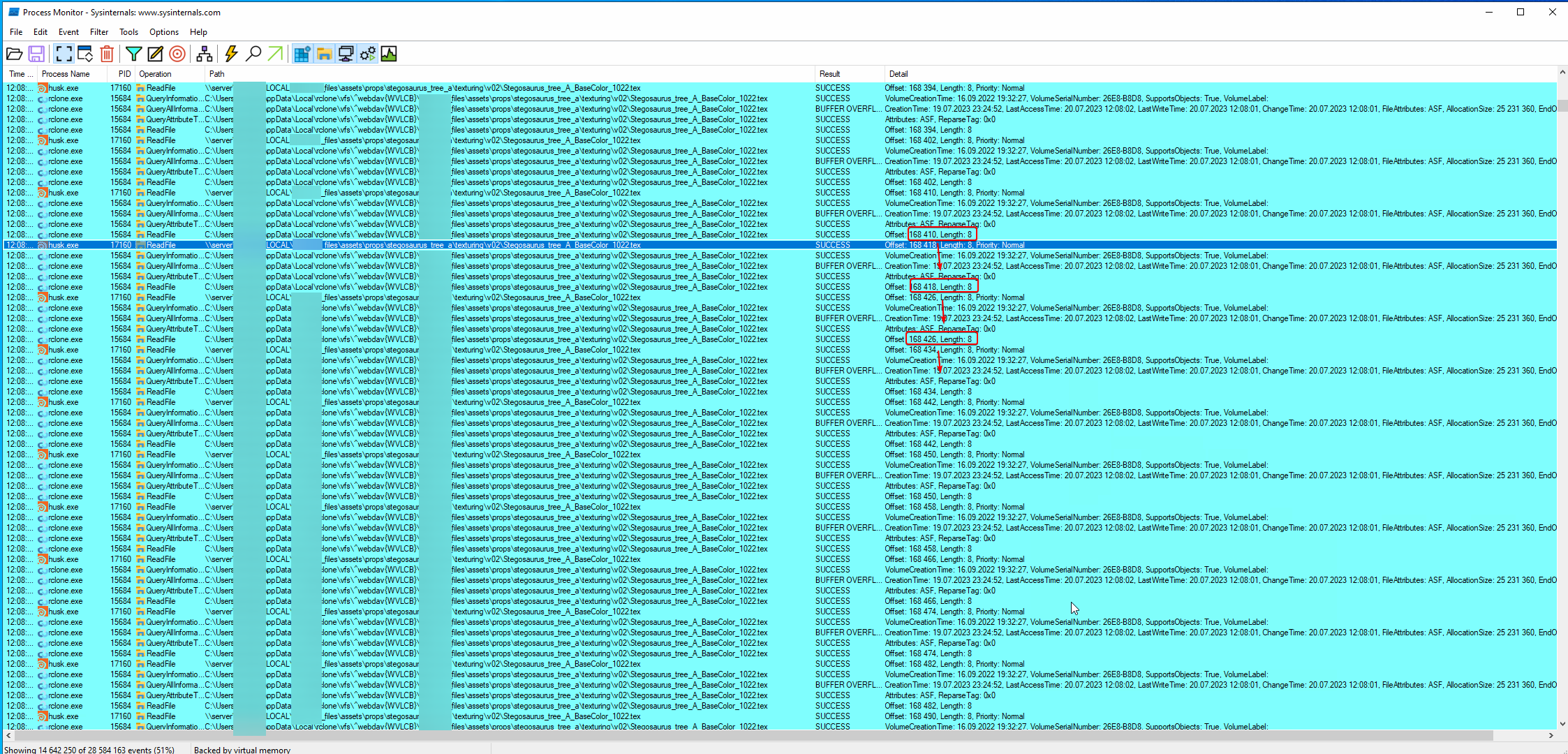
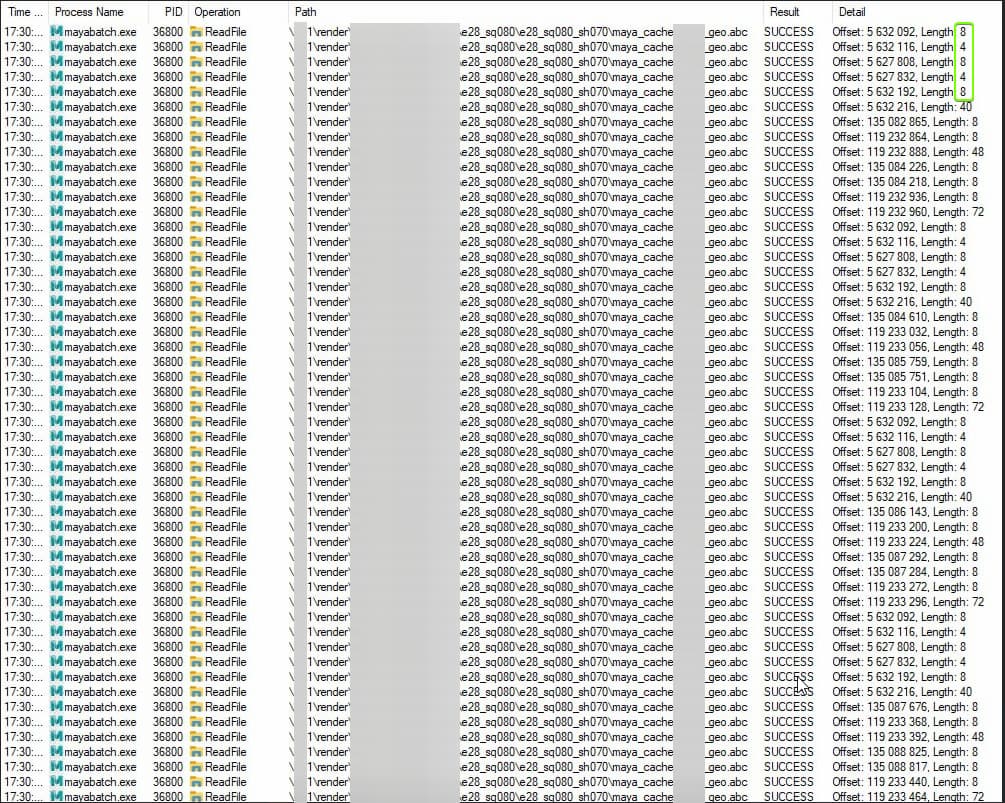
You can see that there is large file that is reading by 8 bytes a call, and it takes 0.5ms, so on large files (100Mi) it is very sensible (compare to 1Mi reading - takes 9ms).
We experience 3 times slower rendering with rclone mounted disks as compared to mounted windows shares with Samba protocol. No matter if it is first render or subsequent with cache populated.
I think it is makes sense to implement some kind of memory caching so subsequent reading would be faster. Have you any ideas on implementing such feature, how memory cache size should be calculated, where it have to be proecessed?
Introduce minimum vfs cache pull limit, say 1024 bytes
download and read local cache in chunks of that size
Use at most 1024 chunks in memory with LRU pull policy for all opened items
So memory consumption will not be significantly increased, and a lot of maintenance will be reduced.
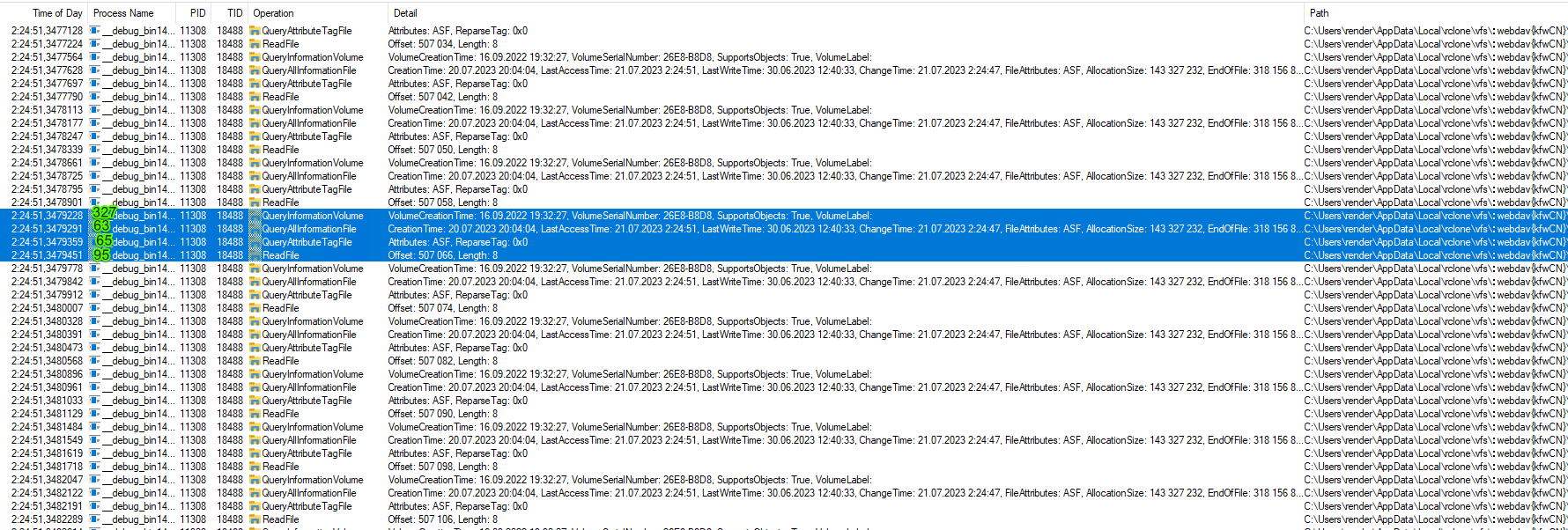
By the way , i found that reading cache file require read permission each read (even 8 bytes) checking, it consist of some operations (QueryAttribute, QueryInformation) that takes about 0.45ms, when actual read takes about 0.15ms. So getting rid of those operations would also increase reading speed in small portions.
It hard to say on how long was first QueryInformationVolume, but even second two Queries took 65+63=128 microseconds that is more that actual read of 95 was.
Sure that missed permissions on vfs cache file or accident deletion of file are exceptional cases and should not be checked.
I do not see a difference without --network-mode, only files in cache are additionally populated at the end.
Got some more info:
extra Query* operations do not occur when i read files in simple test Go program (i even copied OpenFile function from rclone/lib and called with same parameters as vfscache do), they are only under rclone.
i see that test program read 5 bytes from a file for 255 microseconds, but extra calls and read itself take only 4.6+5.6+2.6+7.4=17microseconds, so optimization for that calls may not change it a lot.
I made test for reading single file in portions of different size:
Read 29339600 bytes in 0.025776599999999983 seconds - by 4096 bytes, local
Read 29339600 bytes in 0.15013739999999998 seconds - by 4096 bytes, winfsp-passthrough-fuse3-x64.exe
Read 29339600 bytes in 0.28682240000000003 seconds - by 4096 bytes, samba share
Read 29339600 bytes in 0.31780699999999995 seconds - by 4096 bytes, rclone
Read 29339600 bytes in 8.413499999999999 seconds - by 8 bytes, local
Read 29339600 bytes in 10.6984064 seconds - by 8 bytes, samba share
Read 29339600 bytes in 68.97246200000001 seconds - by 8 bytes, winfsp-passthrough-fuse3-x64.exe
Read 29339600 bytes in 152.11466099999998 seconds - by 8 bytes, rclone
I could conclude that reading big files in small chunks is very inefficient, but samba share client look like have read ahead for sequential reading (and on the web there are some resources that state that). WinFsp introduce significant penalty on reading and rclone double it.
and code as follows:
import time
# f = open('z:\\BaseColor.tex', 'rb', buffering=0)
f = open('C:\\BaseColor.tex', 'rb', buffering=0)
# f = open('x:\\BaseColor.tex', 'rb', buffering=0)
# f = open('\\\\fs1\\share\\BaseColor.tex', 'rb', buffering=0)
s = time.perf_counter()
l = 0
while True:
d = f.read(4096)
if not d:
break
l += len(d)
print(f'Read {l} bytes in {time.perf_counter() - s} seconds')
f.close()
I ve also checked returning zero buffer fill instead on downloading data and pulling localy cached data, so in case of 8 byte reading with 150 seconds i got 125. So i decide that implementing memory caching on rclone level will not change things significantly((
Your results seem to say that the application reading 8 bytes results in a call from the OS to only read 8 bytes.
As I understand rclone logs the best - could you confirm that with the rclone logs with -vv. If I've missed that above - my apologies - I find the screenshots rather hard to read.
What I would expect to happen is that the OS asks for much larger chunks than 8 bytes and buffers them in memory.
Here is what happens under linux when I read a single byte from a file - the OS asks for 16k.
I would expect Windows to be doing something similar and if it isn't we need to tweak it until it does!
That wouldn't be so much of a probem if we weren't doing 8 bytes reads and were doing 16k instead which I think is the underlying cause of the problem.
That is puzzling!
I think you are right. But I think we need to encourage the OS to do it somehow. Maybe there is a WinFSP option which would help...
I just had a look through the code and I think we removed the option by accident in this commit
before this commit we used to supply -o max_readahead=131072 but that seems to have dropped off.
Can you try adding -o max_readahead=131072 to your command line and see if that helps?
@albertony am I reading that change correctly? Did we used to supply max_readahead to Windows and now we aren't?
I can see the reads going through on Windows 1:1 without buffering. I tried adding -o max_readahead=131072 attr_timeout=1 -o atomic_o_trunc which is what went missing but this made no difference at all So it looks like this option wasn't doing anything. I think we should probably put them back though @albertony - the attr_timeout and atomic_o_trunc are important.
Sorry there was mistake on WinFsp github ticket (double assign, that i checked before with no luck), with correct -o FileInfoTimeout=-1 i got read ahead! Speed in my cases is similar to samba share now.
I think probably the -o FileInfoTimeout=-1 should be the default as I don't see why you wouldn't want readahead. We turn it on for Linux and macOS.
It said in the issue linked above that other values such as 1,000 should give readahead but I tried 1000, 1000000 and 1000000000 and none of them gave any readahead.
I shall put this on my list of things to ask Bill about when he is back at his desk.
@albertony thanks for looking at this. I've made a note that this needs looking at but it can wait - no problems.