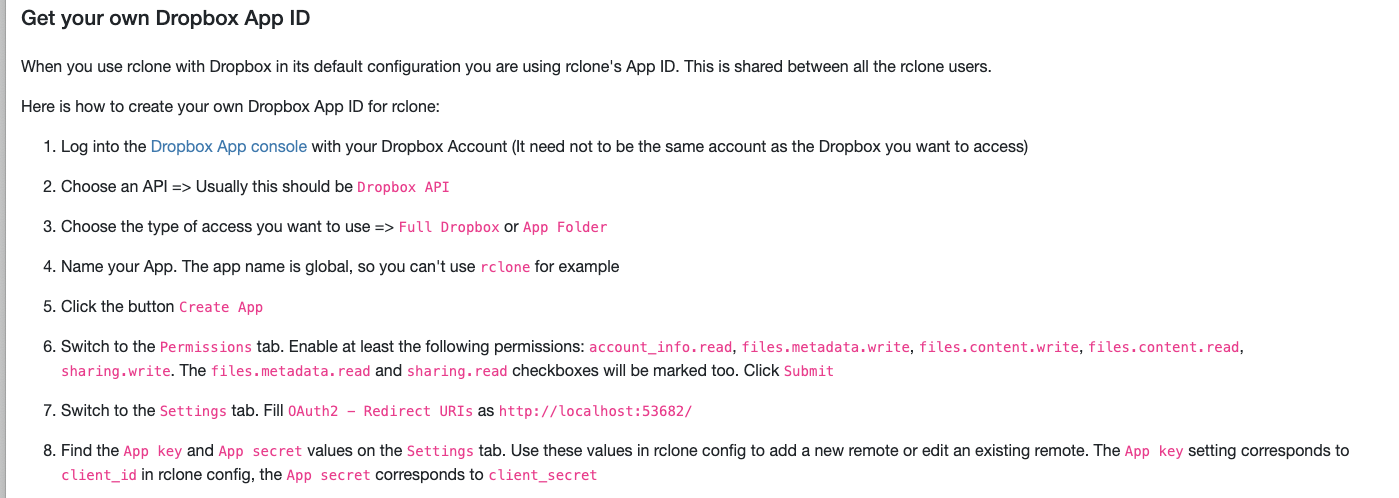
What is the problem you are having with rclone?
I cannot access the HTTP server within Docker, even with the port forwarded.
I did come across Can't access 127.0.0.1:port when using docker which indicates it should work in 1.58 (without any reference), but 1.58 doesn't seem to work for me.
Run the command 'rclone version' and share the full output of the command.
Using the official docker image:
rclone v1.58.1
- os/version: alpine 3.15.4 (64 bit)
- os/kernel: 5.4.0-120-generic (x86_64)
- os/type: linux
- os/arch: amd64
- go/version: go1.18.1
- go/linking: static
- go/tags: none
Which cloud storage system are you using? (eg Google Drive)
Google Drive
The command you were trying to run (eg rclone copy /tmp remote:tmp)
docker exec -it sync_gdrive_ohn rclone authorize "drive" "eyJj......asdf"
The rclone config contents with secrets removed.
[GDrive_setup]
type = drive
client_id = NOPE
client_secret = NOPE
scope = drive
A log from the command with the -vv flag
2022/06/28 17:46:37 NOTICE: Make sure your Redirect URL is set to "http://127.0.0.1:53682/" in your custom config.
2022/06/28 17:46:37 NOTICE: Please go to the following link: http://127.0.0.1:53682/auth?state=ihcW2NL0mmsjOc_8lW3chA
2022/06/28 17:46:37 NOTICE: Log in and authorize rclone for access
2022/06/28 17:46:37 NOTICE: Waiting for code...
Other Input
I noticed when messing with the webgui, it was necessary to set --rc-addr :5572 to bind to [::] or 0.0.0.0... There doesn't seem to be any such option for the authorize server, and thus I believe it is not possible to reach the server in the container, even with forwarding.
Any workaround suggestion would be great, or am I simply missing something? Other than volumes and ports, there are no relevant compose settings, and I can see the port forwarded fine in docker ps.
I did target 1.57.0 via docker and was able to get the classical google URL instead of the local authorize server url, but this is a bit more rigamarole than expected.