What is the problem you are having with rclone?
I'm trying to sync/copy a bucket with 2.2TB of small files (images between 50KB and 500KB) from Digital Ocean Spaces and AWS S3.
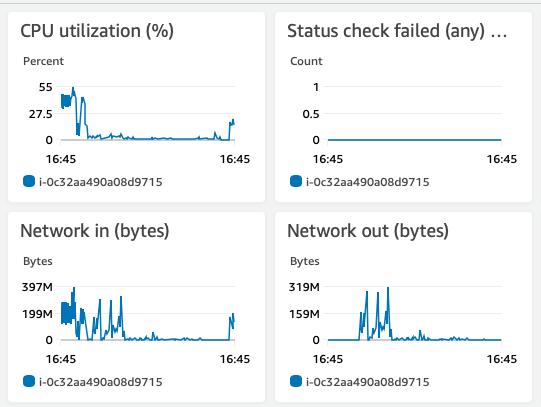
The small number of bigger files (50 files of 3 and 5 GB) were okay transferring. The smaller ones start transferring fast but the speed decreases over time. It starts around 50MB/s and after 10 hours is like 300 KB/s. I'm doing it from a EC2 instance (t2.medium, 4GB, 2 CPU, 30GB Disk with 22 on SWAP) in AWS with Ubuntu 20.04.1.
I tried tweaking the command with some options but without success.
What is your rclone version (output from rclone version)
rclone v1.53.3
- os/arch: linux/amd64
- go version: go1.15.5
Which OS you are using and how many bits (eg Windows 7, 64 bit)
Ubuntu 20.04.1 LTS (GNU/Linux 5.4.0-1029-aws x86_64)
Which cloud storage system are you using? (eg Google Drive)
DigitalOcean Spaces
AWS S3
The command you were trying to run (eg rclone copy /tmp remote:tmp)
rclone --size-only --transfers 8 --checkers 48 --max-backlog 99999999 --retries 999999 --log-level INFO --log-file prodreceipts-"`date +"%Y-%m-%d-%H-%M-%S"`".log sync spaces:receipts AWSS3:receipts &
The rclone config contents with secrets removed.
[AWSS3]
type = s3
provider = AWS
env_auth = false
access_key_id =
secret_access_key =
region = us-east-1
acl = public-read
[spaces]
type = s3
provider = DigitalOcean
env_auth = false
access_key_id =
secret_access_key =
endpoint = nyc3.digitaloceanspaces.com
acl = public-read
A log from the command with the -vv flag
2020/12/28 16:06:44 DEBUG : rclone: Version "v1.53.3" starting with parameters ["rclone" "--size-only" "--transfers" "8" "--checkers" "48" "--max-backlog" "99999999" "--retries" "999999" "--log-level" "DEBUG" "--log-file" "prodreceipts-2020-12-28-16-06-44.log" "sync" "spaces:vexpenses/prod/receipts" "AWSS3:vexpenses/prod/receipts"]
2020/12/28 16:06:44 DEBUG : Using config file from "/home/ubuntu/.config/rclone/rclone.conf"
2020/12/28 16:06:44 DEBUG : Creating backend with remote "spaces:vexpenses/prod/receipts"
2020/12/28 16:06:44 DEBUG : Creating backend with remote "AWSS3:vexpenses/prod/receipts"
2020/12/28 16:07:44 INFO :
Transferred: 0 / 0 Bytes, -, 0 Bytes/s, ETA -
Elapsed time: 1m0.3s
2020/12/28 16:08:44 INFO :
Transferred: 0 / 0 Bytes, -, 0 Bytes/s, ETA -
Elapsed time: 2m0.3s
2020/12/28 16:09:44 INFO :
Transferred: 0 / 0 Bytes, -, 0 Bytes/s, ETA -
Elapsed time: 3m0.3s
2020/12/28 16:10:44 INFO :
Transferred: 0 / 0 Bytes, -, 0 Bytes/s, ETA -
Elapsed time: 4m0.3s
2020/12/28 16:11:44 INFO :
Transferred: 0 / 0 Bytes, -, 0 Bytes/s, ETA -
Elapsed time: 5m0.3s
2020/12/28 16:12:44 INFO :
Transferred: 0 / 0 Bytes, -, 0 Bytes/s, ETA -
Elapsed time: 6m0.3s
2020/12/28 16:13:44 INFO :
Transferred: 0 / 0 Bytes, -, 0 Bytes/s, ETA -
Elapsed time: 7m0.3s
2020/12/28 16:14:44 INFO :
Transferred: 0 / 0 Bytes, -, 0 Bytes/s, ETA -
Elapsed time: 8m0.3s
2020/12/28 16:15:44 INFO :
Transferred: 0 / 0 Bytes, -, 0 Bytes/s, ETA -
Elapsed time: 9m0.3s
2020/12/28 16:16:44 INFO :
Transferred: 0 / 0 Bytes, -, 0 Bytes/s, ETA -
Elapsed time: 10m0.3s
2020/12/28 16:17:44 INFO :
Transferred: 0 / 0 Bytes, -, 0 Bytes/s, ETA -
Elapsed time: 11m0.3s
2020/12/28 16:18:44 INFO :
Transferred: 0 / 0 Bytes, -, 0 Bytes/s, ETA -
Elapsed time: 12m0.3s
2020/12/28 16:19:44 INFO :
Transferred: 0 / 0 Bytes, -, 0 Bytes/s, ETA -
Elapsed time: 13m0.3s
2020/12/28 16:20:44 INFO :
Transferred: 0 / 0 Bytes, -, 0 Bytes/s, ETA -
Elapsed time: 14m0.3s
2020/12/28 16:21:44 INFO :
Transferred: 0 / 0 Bytes, -, 0 Bytes/s, ETA -
Elapsed time: 15m0.3s
2020/12/28 16:22:44 INFO :
Transferred: 0 / 0 Bytes, -, 0 Bytes/s, ETA -
Elapsed time: 16m0.3s
2020/12/28 16:23:44 INFO :
Transferred: 0 / 0 Bytes, -, 0 Bytes/s, ETA -
Elapsed time: 17m0.4s
2020/12/28 16:24:44 INFO :
Transferred: 0 / 0 Bytes, -, 0 Bytes/s, ETA -
Elapsed time: 18m0.3s
2020/12/28 16:25:44 INFO :
Transferred: 0 / 0 Bytes, -, 0 Bytes/s, ETA -
Elapsed time: 19m0.3s
This is part of the logfile I was using to follow the process before: https://pastebin.com/qE2iCM4N
AWS Monitor of the EC2 Instance responsible of running the command: