I just found out that S3 Glacier doesn't support sync --backup-dir command. Given the costs that's reasonable, but can you force it? If server side copy is unavailable can you make rclone delete the file first and reupload it if a file changed? Equivalent to --delete-before flag in rsync (I think).
If you know that a directory won't change much except for a few small files that would be really helpful. I realize how easily you can shoot yourself in the foot, but that's still better than having to reupload everything all again. You can always measure the amount of changes first and limit it to avoid a huge bill from AWS.
In the post above it was mentioned that you can use copy --immutable instead - I don't understand how that replaces sync if you need to replace changed files?
Or is S3 Glacier Deep wrong tool for the job and you should choose another remote to store 100TB+ ?
Or should you not use rclone for this purpose and go for rsync --delete-before and only mount these remotes with rclone?
Run the command 'rclone version' and share the full output of the command.
2023/07/10 05:26:20 Failed to sync with 192 errors: last error was: InvalidObjectState: Operation is not valid for the source object's storage class
status code: 403, request id: <REQUEST-ID>, host id: <HOST-ID>
It is nothing about cost. rclone sync --backup-dir requires server side move operation which is not possible with glacier. rclone sync can work without any issues and will update changed files. You only have to remember that you always pay for 90 or 180 days of storage depending on storage class (glacier vs deep glacier). So if you have 1GB file changing daily synced to deep glacier at some point it will cost you 180 time more to store this 1GB file there.
Oh I see, sorry that makes complete sense. It's not the rclone sync that gets blocked by lack of server-side copy - it's the --backup-dir option, which requires you to copy the previously stored file to a backup directory?
it will cost you 180 time more to store this 1GB file there
makes sense, so you should run sync only once every 90 days or so. What happens though if you lose some files and you won't realize it within these 90 days? They will get deleted on AWS archive as well? Without backup-dir they will be gone forever?
I guess you could create multiple full archives that get synced every 90, 180, 360 days and so on, but if you don't change files that often that's a lot of unnecessary redundancy.
I suppose that theoretically you could have server-side copy with glacier if you kept a list of changed files and run a cron job after the files are available. But that would take a lot more work to setup.
How often you want to sync is entirely up to you - but every time you put file into glacier you incur 90 or 180 days storage charge - even if you delete it next minute.
yes. It is possible to build such functionality:
get list of changed files in data folder
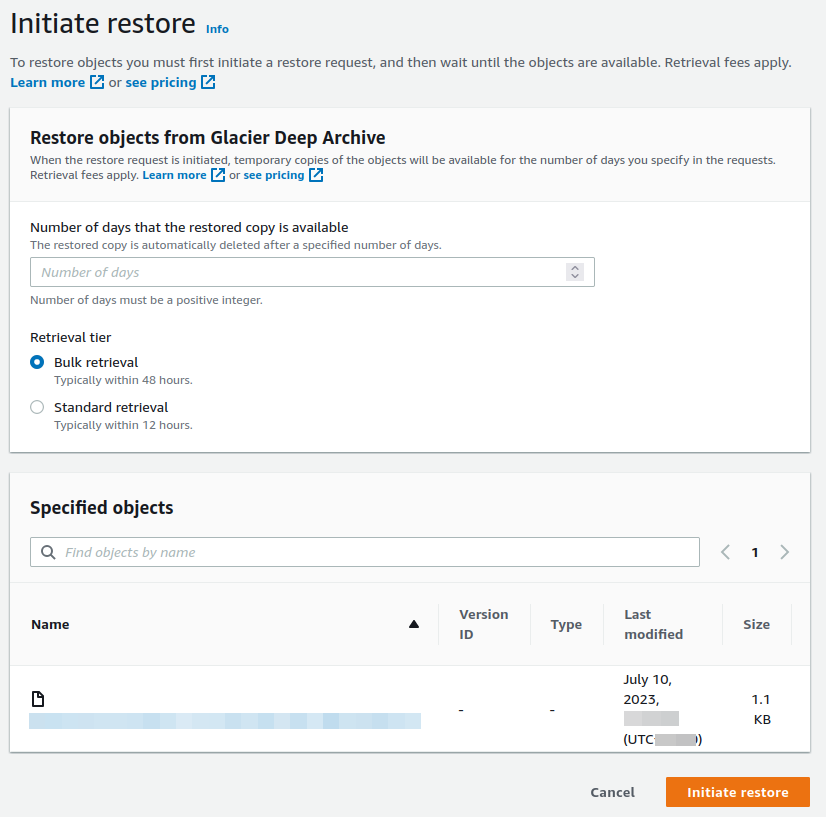
run rclone backend restore for all of them
Up to 48 hours later (for deep glacier bulk retrieval) you can server side copy files to backup folder with glacier storage class transition (so they end up back in glacier again)
After you wrote it down, it doesn't sound so complicated actually. The problem is knowing though when to restore them - the exact time varies. This probably would need to be a "lambda" triggered by AWS event notification or maybe there is some daemon on linux that can be notified?
You also need your source data folder to stay unchanged when you wait for retrieval for this to work reliably. As if more files changes you have to start all process again before running sync. So what seems at the first look as simple algorithm quickly can become quite complex when dealing with all possible situations/errors and edge cases.
Yeah, I may look at backblaze first maybe it will be simpler (pricinig seemed comparable and I assume that their storage retrieval is always instant). Thanks again anyway, I may try to implement this though if backblaze won't work. If there is another service for storing 20TB+ that you would recommend it would be definitely very helpful.
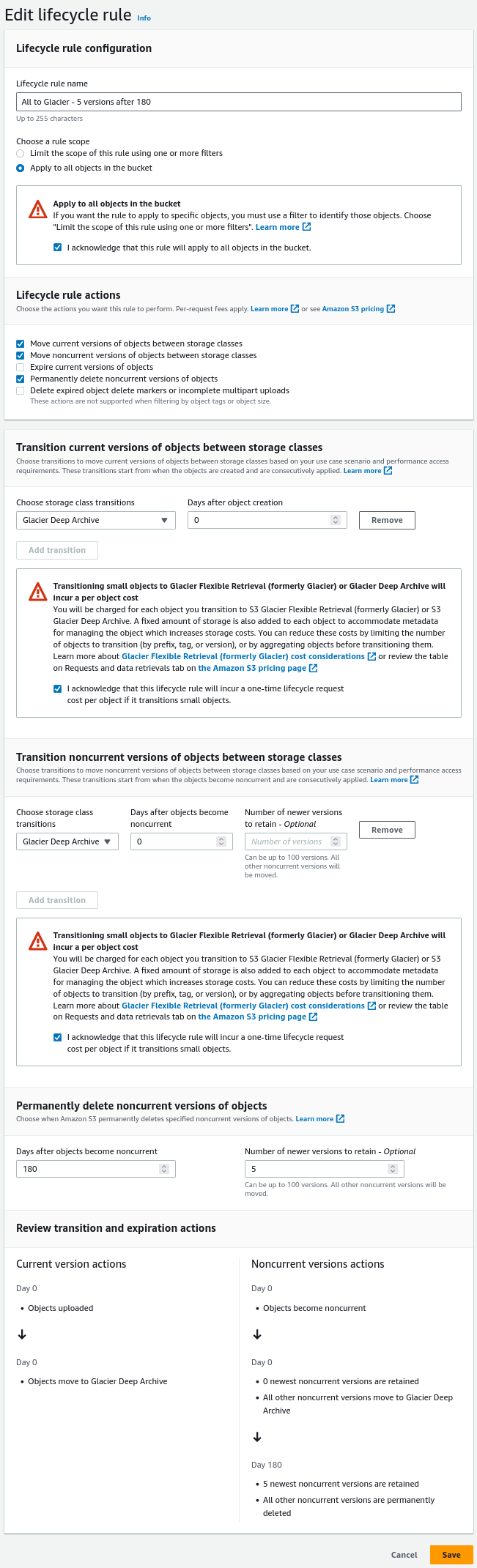
I would create a bucket - then using AWS console enable versioning and add lifecycle rule to move everything (current and not current versions to Glacier after 0 days). So effectively anything put in this bucket would end up in glacier - no need to specify storage class in rclone. Now I could sync to this folder anytime without thinking too much.
You can fine tune how many versions should be kept or for how long. E.g. does not make sense to delete any version before 180 days (for deep glacier) as you pay for its storage anyway.
Rclone has very cool feature in versioning support - s3-version-at - using it you can list bucket as it was at any given date and time.
What I am not entirely sure is how s3-version-at cooperates with rclone backend restore - something you should probably give good testing - it should work as any other filters.. but I doubt many people use it so can be some surprises:)
All together would be much more powerful and sophisticated than crude backup-dir flag approach.
You can fine tune how many versions should be kept or for how long. E.g. does not make sense to delete any version before 180 days (for deep glacier) as you pay for its storage anyway.
I wouldn't have thought about it. One thing I'm missing though (or I didn't get right) is being able to specify "exponential" increments (for example 3 monthly and 2 yearly versions). But these syncs are so infrequent that you may as well just use "5 latest versions".
While this isn't an AWS forum, do you remember by any chance if you specified number or versions in noncurrent versioning dialog or left it blank? Not sure if left blank it will keep maximum number of versions possible (100) or none at all.
I'm looking forward to find out how restoring previous versions will work. Thanks a lot for mentioning --s3-version-at (and --s3-version) option. I'm going to sync this bucket again now and test them.
By the way I wouldn't have thought about looking at the option "Permanently delete noncurrent versions of objects" at first, so thanks as well for mentioning that it's possible to specify maximum number of days. Option "Days after objects become noncurrent" didn't sound at first like "after objects becomes noncurrent wait for this amount of days" and more like "make these object noncurrent after this amount of days". But hopefully it will work now (and these new lifecycle charges won't be too taxing).
Yes there is no such option in AWS but as with rclone you can list versions with --s3-versionsyou could do a bit of bash kung-fu and implement whatever suits you. Deleting from glacier always works:) You do not have to worry about it for 180 days... so can be project part 2.
rclone -q --s3-versions ls remote:path/to/object didn't seem to work - only the current version was listed. But aws-cli seemed fine: aws s3api list-object-versions --bucket <BUCKET> --prefix <PATH/TO/OBJECT>
Initiating restore doesn't seem to list the object versions yet, but maybe they will show up after third version (unless you need to restore object as a whole including all its previous versions)
rclone -q --s3-versions ls remote:path/to/ --include 'object*'
mind the asterisk at the end and single quotes around object.
This is also a really useful way to find which objects have versions (just grep or --include a suffix like -v2023-07-08 to find versions from 8th of July 2023) - previously I had to list files by most recently changed (and that not always worked).