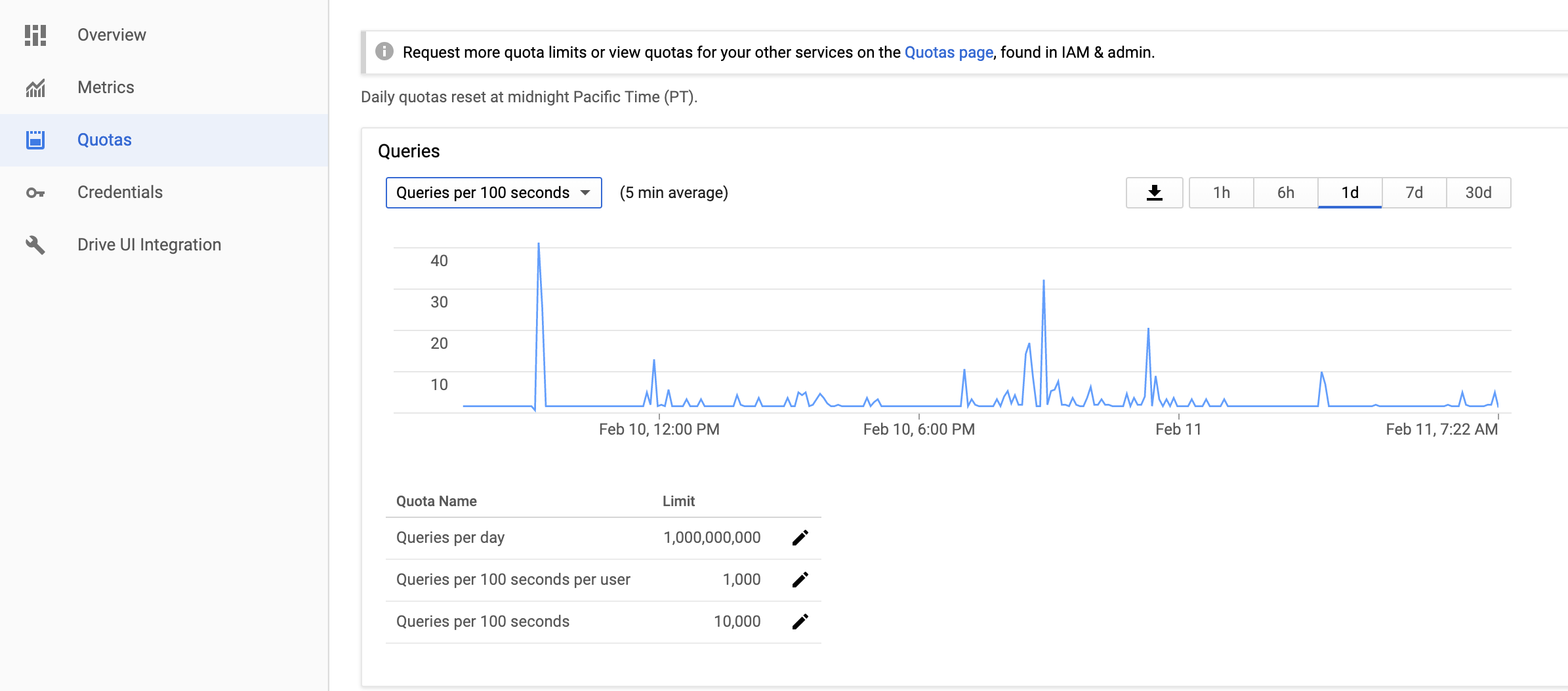
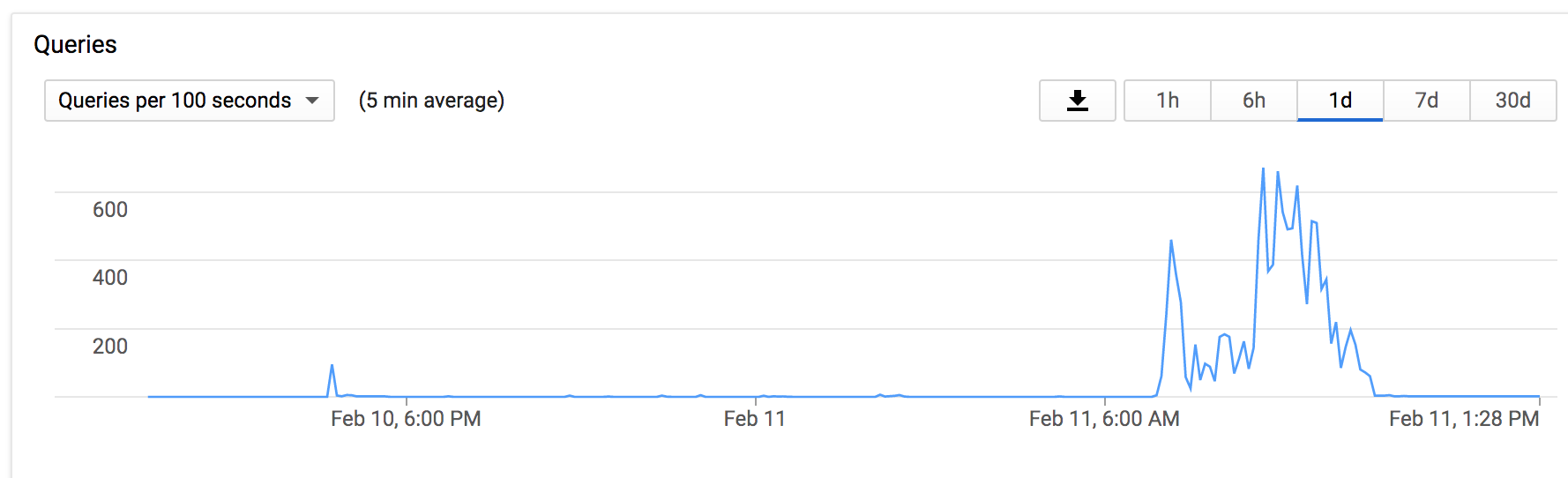
I have two machines making use of a Google Drive backend.
Machine A lives in a data center and prepares files locally and then uses rclone to copy them to Drive.
Machine B mounts the drive locally at home.
These two machines have been running cron jobs happily for at least 18 months with no hiccups.
Over the weekend I notice that an rclone job that syncs the Drive to another Drive (a backup mirror) had been hung since November.
I killed that job and tried restarting the sync, but I get 403 Rate Limited Exceeded errors constantly and the transfer rate sits at 0. I stopped the cron job to give it a rest (e.g., if there is some kind of 24 ban going on).
But now Machine A simply cannot upload anything to Drive.
The instant the transfer starts, the log fills up with:
2019/02/11 11:16:13 DEBUG : rclone: Version "v1.46.0-006-gef5e1909-beta" starting with parameters ["rclone" "copy" "-c" "--stats" "3m" "--tpslimit" "3" "--transfers" "3" "--files-from=/tmp/files" "-vv" "/mnt/media/Drive" "GoogleDrive:"]
2019/02/11 11:16:13 DEBUG : Using config file from "/home/chezmojo/.config/rclone/rclone.conf"
2019/02/11 11:16:13 INFO : Starting HTTP transaction limiter: max 3 transactions/s with burst 1
2019/02/11 11:16:13 DEBUG : pacer: Rate limited, sleeping for 1.499745568s (1 consecutive low level retries)
2019/02/11 11:16:13 DEBUG : pacer: low level retry 1/10 (error googleapi: Error 403: Rate Limit Exceeded, rateLimitExceeded)
2019/02/11 11:16:14 DEBUG : pacer: Rate limited, sleeping for 2.234574878s (2 consecutive low level retries)
2019/02/11 11:16:14 DEBUG : pacer: low level retry 2/10 (error googleapi: Error 403: Rate Limit Exceeded, rateLimitExceeded)
2019/02/11 11:16:15 DEBUG : pacer: Rate limited, sleeping for 4.7689464s (3 consecutive low level retries)
2019/02/11 11:16:15 DEBUG : pacer: low level retry 3/10 (error googleapi: Error 403: Rate Limit Exceeded, rateLimitExceeded)
2019/02/11 11:16:17 DEBUG : pacer: Resetting sleep to minimum 100ms on success
2019/02/11 11:16:22 DEBUG : pacer: Rate limited, sleeping for 1.230433586s (1 consecutive low level retries)
2019/02/11 11:16:22 DEBUG : pacer: low level retry 1/10 (error googleapi: Error 403: Rate Limit Exceeded, rateLimitExceeded)
2019/02/11 11:16:22 DEBUG : pacer: Rate limited, sleeping for 2.932044098s (2 consecutive low level retries)
2019/02/11 11:16:22 DEBUG : pacer: low level retry 2/10 (error googleapi: Error 403: Rate Limit Exceeded, rateLimitExceeded)
2019/02/11 11:16:23 DEBUG : pacer: Rate limited, sleeping for 4.806679986s (3 consecutive low level retries)
2019/02/11 11:16:23 DEBUG : pacer: low level retry 3/10 (error googleapi: Error 403: Rate Limit Exceeded, rateLimitExceeded)
2019/02/11 11:16:26 DEBUG : pacer: Resetting sleep to minimum 100ms on success
The log just goes on and one like this for hours with a transfer rate of 0:
Transferred: 0 / 0 Bytes, -, 0 Bytes/s, ETA -
Errors: 0
Checks: 0 / 0, -
Transferred: 0 / 0, -
Elapsed time: 3h6m1s
If I run the same command against a different Drive the log fills up with the same errors, but then actually manages to transfer files after a while.
I created a new API key and refreshed the tokens to effect.
I updated to the latest rclone Beta to no effect.
Machine B is doing fine — no errors in the log (for the mount).
And the sync job is now running fine on another machine.
Just to be clear, I changed absolutely nothing about my setup. These 403 errors cropped up suddenly and without any obvious proximate cause.
Is anyone else running into anything similar?