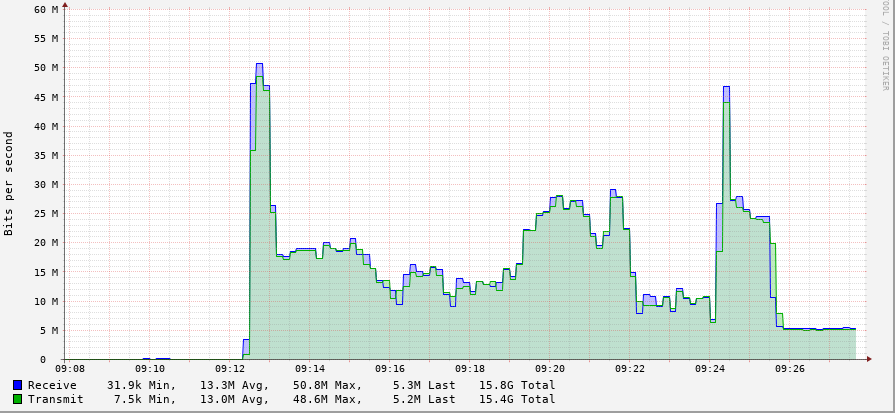
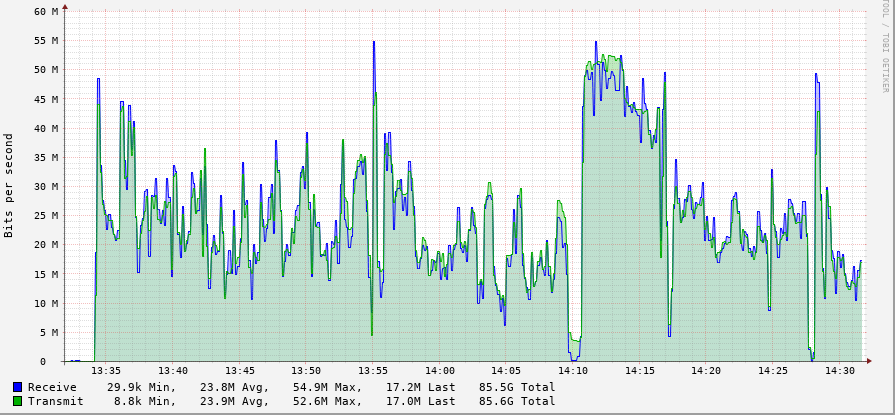
I am experiencing a rather strange phenomenon lately.
When i access a file trough a rclone mount the transfer starts very fast but at some point drops dramatically to ~5mbit/s and stays there for all subsequent chunks the ChunkedReader loads.
I tested it with rclone v1.44, v1.43.1 & v1.42. The result is not always 100% reproducible but will always occur eventually. One interesting thing i observed is, that if i read the file at full speed (into /dev/null) the speed will not decrease at all until the transfer is complete.
I tested it with "pv -L 1500K /mount/rclone/test.file >/dev/null" to mimic reading at lower speeds and i was able to reproduce the sudden drop in download speed.
This is a graph of 3 downloads of the same file with 3 rclone versions showing the described problem.
The server running rclone is connected with 1 gigabit (unthrottled) and has an excellent peering to the google servers. The issue started to manifest a few days ago. I tried using the gdrive v2 api which unfortunately did not help in this case.
(After many tests i intentionally added the chunk size limit of 8M to limit the effect on the daily gdrive download limit.)
Do you guys have any ideas or input on this issue? The debug log does not show anything unusual except it reads at a lower speed (no 403s or other errors)
Can you check the things around rclone? I copied a few files and can’t reproduce the issue. Forcing it down to 8M chunks would generate a lot of API traffic for a file copy so I wonder of that has something to do with it.
Is it your own server? A VPS through a provider?
I let a few copies run for 10 minutes or so and do not see the issue as it stays consistent at very good speeds.
felix@gemini:/gmedia/Radarr_Movies/Ready Player One (2018)$ rsync --progress Ready\ Player\ One\ \(2018\).mkv /data
Ready Player One (2018).mkv
16,445,636,608 23% 91.15MB/s
API traffic with 8M chunks is really not an issue and stays well within limits even with 10 simultaneous transfers (checked in api console). It doesn’t really matter for this issue if i choose 8M,16M or higher values (i tested with several values). I just didn’t want to run into any issues with the daily/hourly download limits on gdrive during testing (initial values were up to 512M chunk size)
The most curious thing is , as mentioned earlier, if i run a transfer at full speed (like your rsync copy to /dev/null ~30MByte/s with 8M chunks) it will never run into this issue, only if the file is read at a lower pace.
Are you able to check with iotop and see if something is IO bound for whatever reason? It feels like something else on the system is a bottleneck, but not sure what if the /dev/null copy is working that would rule out CPU/Memory/Network for me unless I’m missing something.
The only thing left would be Disk or something specific with rlcone itself.
I can rule out an IO bottleneck as well as CPU limitations. The system is barely doing anything during the transfer. Network is also tested and working up to sustained 900mbit/s. None of the transfers saves anything to the disk.
Since this started “out of the blue” and is also present in earlier rclone versions, it is more likely the sender is doing “something” - in this case gdrive. I just haven’t found out HOW or WHY…
Mine grabs the 10.42 first but you could pick from one of the other 10 or so IPs it resolves to and try to force it to a particular end point and see if anything changes.
i tested it with several specific google api endpoints one after another , specified in /etc/hosts . (i had to compile my own rclone version to be able to use export GODEBUG=netdns=cgo )
no luck here is another example graph of what is happening. you can clearly see the limiting at the end to almost exactly 5mbit/s. Again, if i load the file at full speed, the limiting never kicks in…
@ncw is there any possibility that some bandwidth rate limiter part of rclone is going haywire under special circumstances? Debug log shows nothing out of the ordinary
thank you for this info! the server is indeed currently running "4.15.0-36-generic"
i will test a downgrade or upgrade to proposed 4.15.0-37 wich apparently already has the fix
I upgraded the Linux kernel to bionic-proposed 4.15.0-38-generic and tested the same configuration with several different files at random speeds, just as before.
I would never have guessed this could be a kernel bug… but the results do speak for themselves. Not a single bandwidth drop in roughly 1 hour. It is too early to say this issue is completely gone , but it looks very promising.
Oh those aren’t fancy graphs. That looks to be simple ones
If you want graphs, check out netdata as I store all that in influx and use grafana to visualize the data.
I went from .33 kernel to .38 and didn’t have the speed issues but a different one.
I download stuff using JDownloader and then extract it directly to the mount. From there I move the files to a specific movies/shows folder so FileBot can do its magic.
Unfortunately, since the kernel update there seems to be something wrong, whenever I move the files into the “sort-folder” some of them are missing.
My mount is rclone_1.42 mount --allow-non-empty --allow-other --dir-cache-time 8760h --poll-interval 0 --vfs-cache-mode writes --vfs-cache-max-age 0m --vfs-read-chunk-size 64M --vfs-read-chunk-size-limit 2G --drive-use-trash=false upload: /media/cry
Rclone version is 1.42 stable. I moved to 1.44 after the kernel update and thought this issue would be related to the new rclone version thus went back to 1.42 but the problem persists.
Anyone having the same issue?
I will move to 1.44 and activate debug log, let’s see if we can narrow this down.
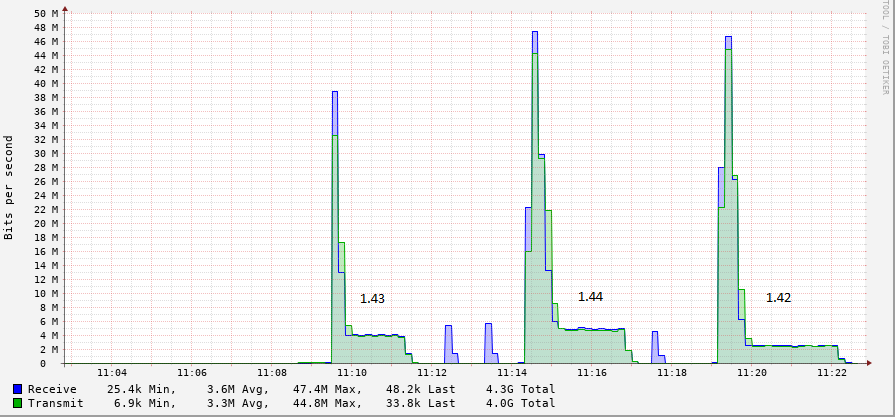

 here is another example graph of what is happening. you can clearly see the limiting at the end to almost exactly 5mbit/s. Again, if i load the file at full speed, the limiting never kicks in…
here is another example graph of what is happening. you can clearly see the limiting at the end to almost exactly 5mbit/s. Again, if i load the file at full speed, the limiting never kicks in…