hello all, was doing some experiments and curious if people have had any experience in this regard
rclone chunk -> rclone crypt -> box - works like a champ, on a 5 gb max account
hopefully this makes sense.....
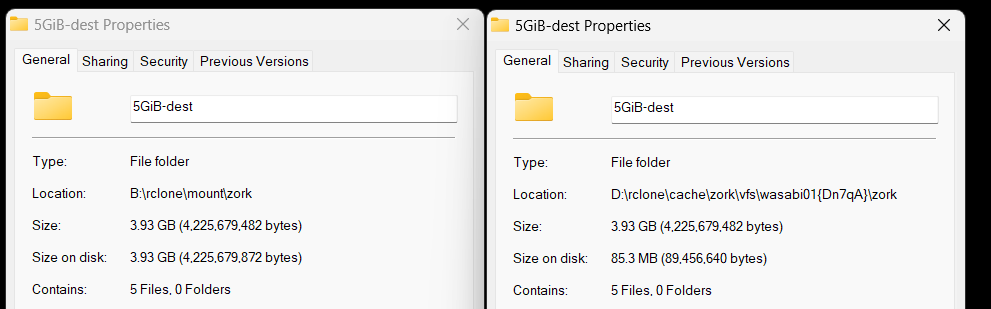
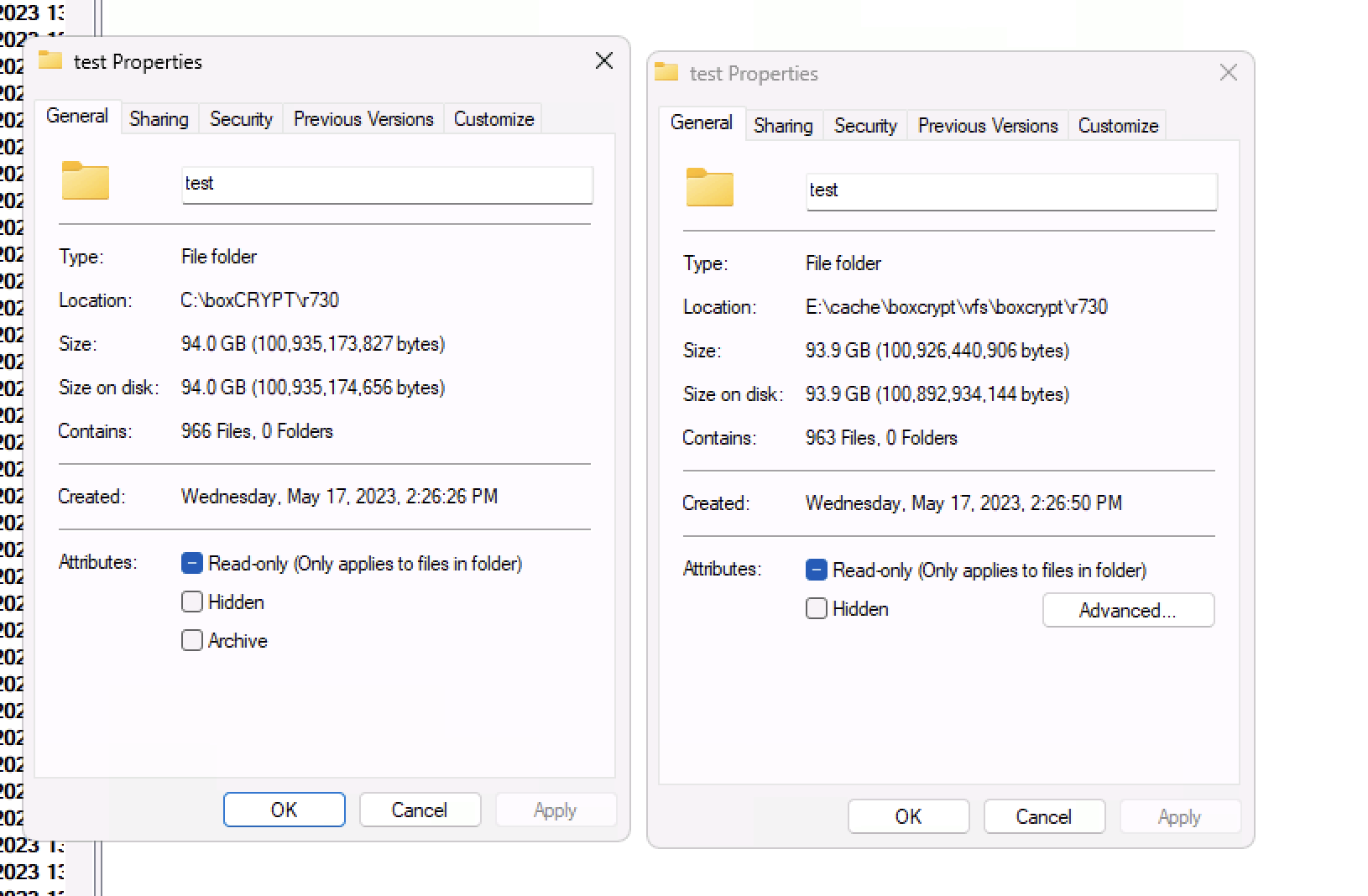
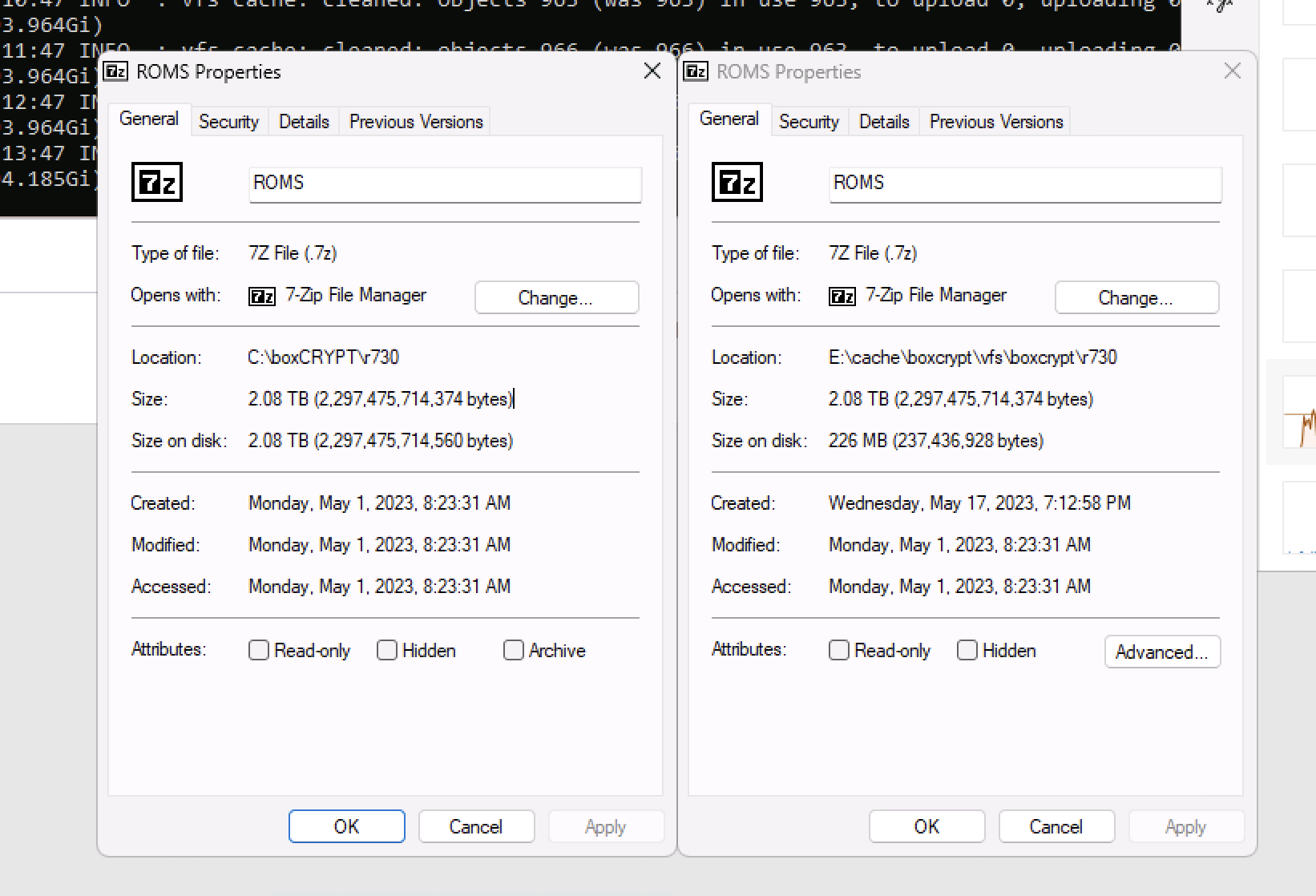
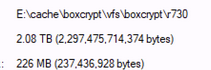
I had some large archives of very seldom used stuff - I created a 2.2 tb .7z file - copied it (which rclone - chunked fine) - and with rclone mount it certainly appears that it was able to read the header very quickly in 7zip (it certainly wouldn't be in local cache) and extracting random files from within the archive was quite fast.
however when I try this with (say) a 100 gig file that is in 50 2gb .7z chunks - it seems like it needs to scan (aka download to the cache) all the pieces.
I guess this is more of a deep .7zip question but wondering if anybody has played around with any archiving solution + rclone mount and what their experience might be.
really interested in being able to put split archives up bypassing rclone chunking if possible.
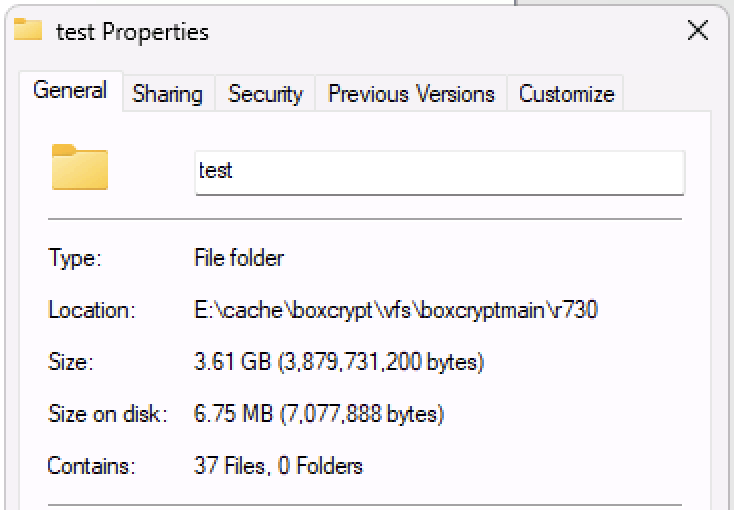
Interesting I never saw partial items in cache , it sure looked to me like it was downloading all the objects into cache - which backend did you test on?
Edit: I see it’s on wasabi - I wonder if that makes a difference
just tested the 900 piece file with a nuked cache, same thing - downloading all the pieces individually (still going in the b background as I write this) full copies of each file - very odd - sort of seems like a 7z thing I wonder what's different
for reference, mount command:
rclone.exe mount boxcrypt:/ c:\boxCRYPT --transfers 30 -v --vfs-cache-mode full --no-checksum --vfs-fast-fingerprint --vfs-read-chunk-size=512M --vfs-read-chunk-size-limit=off --vfs-read-ahead=512M --checkers=8 -cache-dir e:\cache\boxcrypt -
went back to the docs, taking a stab at this - I think --vfs-read-chunk-size=512M is the problem here, since in my test case the files are 100 meg it's just going to read the whole thing right?
You'll have better luck with .zip files. These have a central directory stored at the end so the unzipper should only have to read the last chunk. I've tested this is the past and it worked very well.