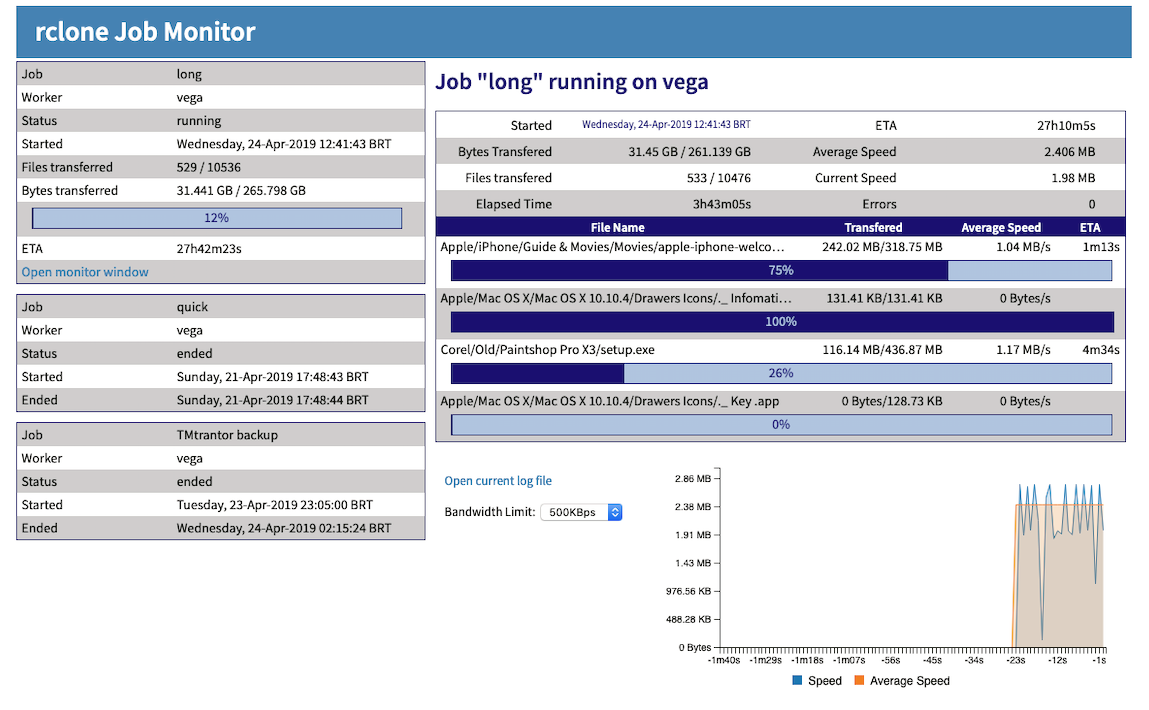
To be clear I’m talking about the wobble not the sharp peaks. Even with a speedcap I still get wobble.
Here I’ve set a speedcap of 8 mebibytes per second (MiBps) = 1048576 Bps and I still get wobble:
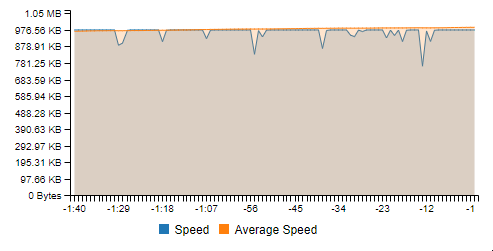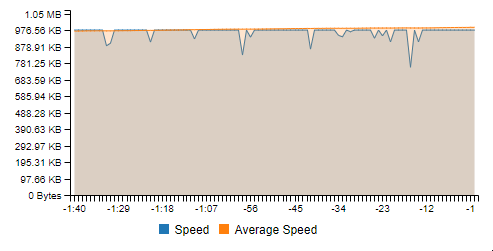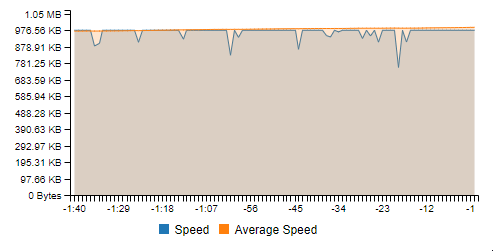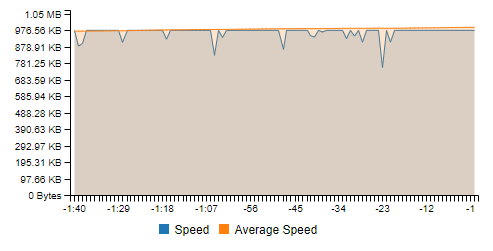
To be clear I’m talking about the wobble not the sharp peaks. Even with a speedcap I still get wobble.
Here I’ve set a speedcap of 8 mebibytes per second (MiBps) = 1048576 Bps and I still get wobble:
Ohh… sorry I read too quickly and missed the actual question.
Can you try a simple mod to rcloneMon.js?
After line 230, add:
transition:{duration:0},
It should look like:
chart=c3.generate({bindto: '#chart',
data:{columns:[speedArray,speedAvgArray],
types:{'Speed':'area','Average Speed':'area'}},
point:{show:false},
transition:{duration:0},
size:{height:240,width: 480},
types:{'speed':'area-spline','Average Speed':'area-spline'},
axis:{y:{tick:{format:function(d){return d.toString().formatBytes();}}},
x:{tick:{format:function(d){var t=100-d; return '-'+t.toString().formatSeconds();}}}}
});
It don’t bother me, but I will add it to the code (lots of changes already in, but not finished). I can see it’s quite annoying over time.
And be careful not actually chop your graphic, but setting a value of speedcap too low. It’s intended to prevent really big outliers.
I’ve added it. Had to remember to shift refresh.
Thanks, that has fixed it. I see the issue now. As the graph was scrolling it was transitioning between the last (x,y) coordinate that used to be there, not changing the data point itself.
The clipping I showed was just an example to point out the cap didn’t work.
Regarding smoothing out the spikes, I believe the curve factory can help with this or you could add a 3-second rolling average.
As I said, there are many ways to do it, and it’s on the pipeline.
The beauty of the current solution is that it’s very simple to manage the results array (cap incoming, shift in, shift out old). So it was the quick-n-dirty solution.
BTW, anyone knows a way to obtain the current bandwidth setting?
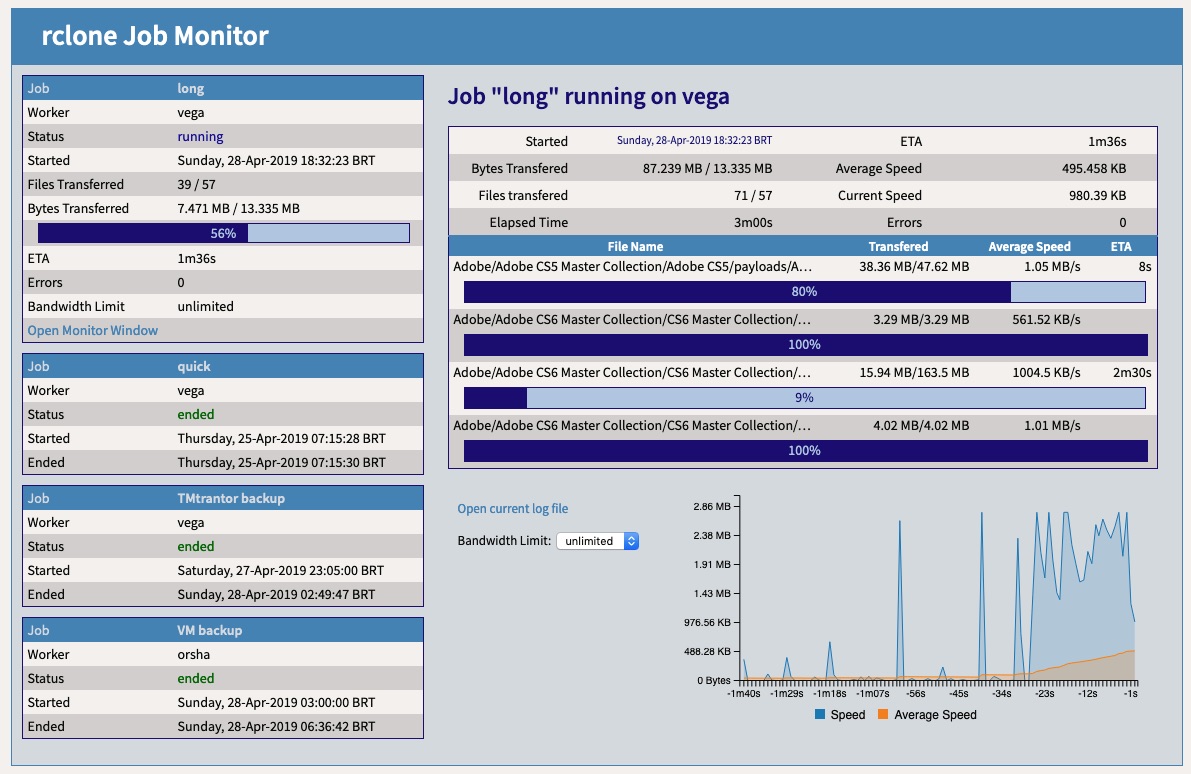
This is a sneak peek of the next version. It includes:
If anyone has any suggestion for the interface, please let me know. In theory the only piece missing is the job termination exit, to allow messaging the user (for better babysitting of jobs).
Note: the full job list GUI requires a permanently running HTTP server, to serve static files only. So one can use a full HTTP server like Apache or even rclone --rcd
Looks nice. Never managed to get the bw limit to work though.
Do you have a release date in mind?
I still don’t really get the point of the server > name and jobs > server fields as they seem completely arbitrary as long as they match. Likewise, jobs > name doesn’t seem to do anything at all other than restrict/require the URL query string.
First let me tell that I've renamed "server" to "worker" in the new version. This should help with some confusion with a physical computer/server.
If your point of view is a single job, having a worker/job organization can add some undesirable confusion. But if you have many different jobs and possibly more than one physical server, then the idea of workers/jobs makes a lot of sense to manage multiple jobs.
Using the "new" naming, one computer (desktop or server) can host multiple instances of rclone. These rclone instances are what I call worker. To be effective, each worker must assume a different TCP port for remote control. This way even on a single host, it's possible to run multiple workers (rclone instances).
In theory, a rclone worker or instance can execute a single synchronous job and/or multiple asynchronous jobs. I said in theory because the API, as it is today, does not provide enough information to allow monitoring multiple jobs on a single worker - if they are running at the same time. So the idea of a worker makes a lot of sense to differentiate between multiple rclone instances on a host and provides a sane concept to allow for multiple jobs on a worker in the future.
Likewise, one can define multiple jobs, for a given worker or for multiple workers. Since there is not way at this time to accurately monitor more that one job on a single worker, right now it's advisable to limit each worker to one single job (unless you can be 100% sure that they will not run in parallel). The concept works now and is also functional when the API evolves to contemplate monitoring multiple jobs per-instance.
The worker name is there to allow jobs to select the worker, as there job name allows for the GUI to select which job to monitor. They are just pointers, nothing more.
For example, I'm currently testing in the following scenario:
cron.So I have a single config.json with 4 workers and 8 jobs. The same config.json is used on both NAS boxes (see further for the reason), as they both share the same rclone.conf.
Jobs (except for the test ones) are fired from cron.
I can point the browser to either NAS box and they will show me a list of the 8 jobs I have, with current status of each one (running/ended/failed). If running, the list includes the ETA and progress and allow to fire the full monitor on the right.
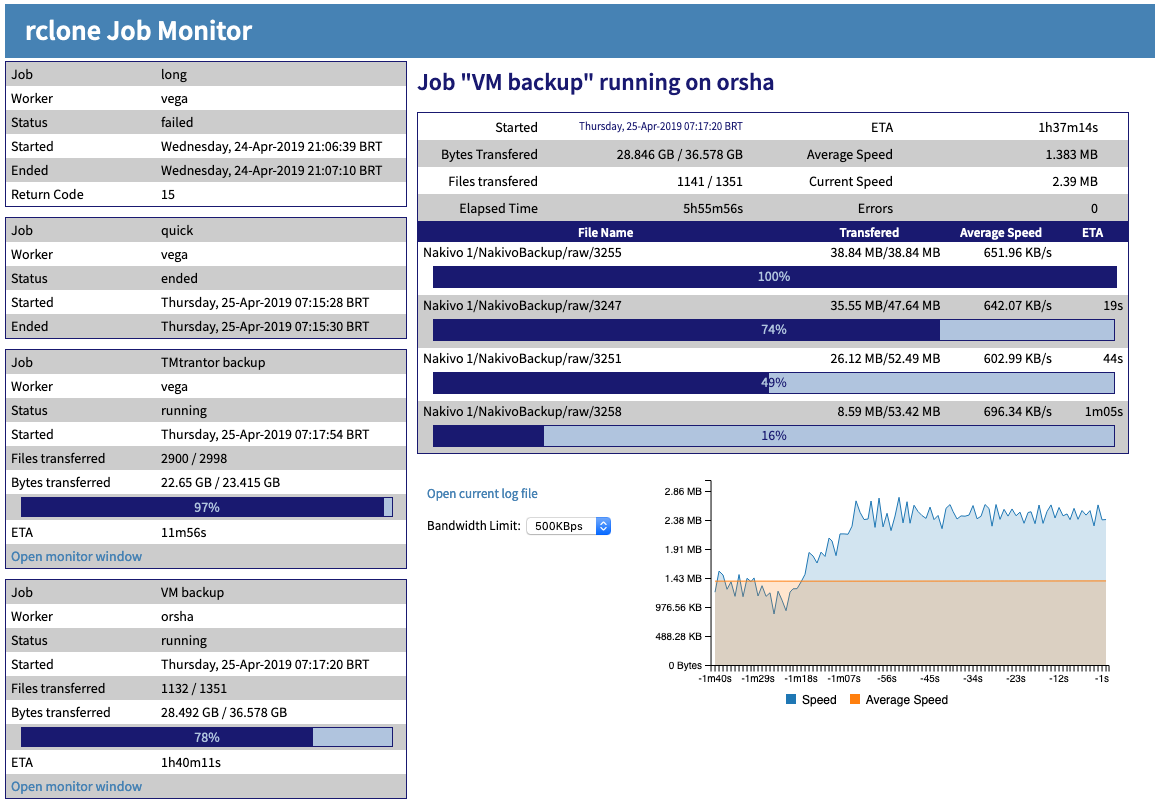
This picture (similar the one in a previous post) shows 2 jobs running on different workers with one of them on the full monitor.
So if you look with the single job perspective, it's not that straightforward to grasp the concepts. But if you need more than a single job, this can be easily represented and allows for the future API enhancements.
Hope this clear things a little.
As for the time frame, I just fixed a nasty DOM bug with the progress bars and will wrap the Notifications (email/SMS/Push) soon. I hope to get it out during the weekend. The hard part is to write the documentation.
Thanks for all that and the timescale. Yeah, that makes a bit more sense now.
Can I clarify about bandwidth? Is that meant to dynamically change the bandwidth allocation of each worker on a particular job? Do you need to start the copy or sync or whatever with a bandwidth restriction for it to work?
When showing the full job monitor (that is the version you have changing the dropdown will send a command to the corresponding worker to change the bandwidht. I’m using it when I need to “reserve” some bandwidth when I’m streaming.
I start rclone without any particular bandwidth setting. The only restriction if to properly set the values you want in the config.json file. Keep an eye on the log while testing it. It will display any errors you have. It works great for me.
Checked the job on the command line and it does seem to be sending the limits through okay actually. Is the default selected bandwidth applied when the page is loaded or only if you use the drop down to select something?
The bandwidth will only change if you change the value that is being displayed.
The initial value is the first on the config.json file, as there is no way to determine the current setting. It only displayed but not changed to. If / when I find a way to query the current bandwidth setting, I will change the behavior.
I know it’s not ideal, but better than nothing. It still allows one to change the bandwidth limit using the GUI.
Thanks that makes sense. I’ve reordered mine and set Unlimited/off to be the default as I feel that’s more likely to be the case for a given job. You could always make the page toggle between a setting and the first in the drop down if users wanted it to set to the top option too.
There is a problem with that: one can get in the page at different times and that would cause the bandwidth limit to be changed to the “default” each time.
As for a initial setting, this can be set on the command line and have the first setting matching. Will work provided that you don’t change and reload the GUI.
This approach gives me an idea of how to mimic getting the current setting, if rclone is started from my wrapper script. Will try and post the results!
UPDATE
Got it to work. Now if using the wrapper script it’s possible to have an acceptable way to retrieve the current bandwidht limitation even across entries of the monitor GUI.
Hope to have it out over the weekend.
Just uploaded version 0.9b to GitHub. MANY changes and new features (too many to duplicate all here).
rclone log file.rclone task (includes persistent job status).NOTE
Please be aware that some options in config.json have changed, specially now servers are called workers (much better choice of name).
Works on Windows Server ?
The monitor part will work (that's showing on the right of the image). But, unfortunately, the wrapper script was designed for *unix type systems. Mostly due to process management routines.