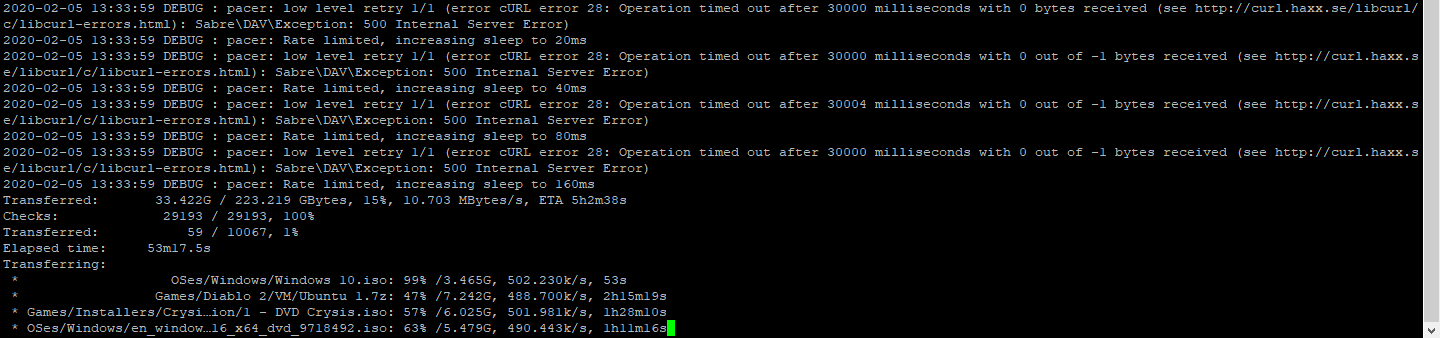
Syncing from on WebDAV to another. There is only 900 GB of data, but it already shows that it has synced 1.6 TB of data. My WebDAV and the Hetzner Storage Box control panel only show 600 GB of usage.
The displayed average transfer speed (10 MB/s) is reasonable, and would mean that it has transferred 1.7 TB of data by now. What is it copying???
What is your rclone version (output from rclone version)
1.51.0
Which OS you are using and how many bits (eg Windows 7, 64 bit)
Debian 9, 64 bits
Which cloud storage system are you using? (eg Google Drive)
WebDAV (backed by Nextcloud)
The command you were trying to run (eg rclone copy /tmp remote:tmp)
More details. I watched a bit closer and it seems that once a transfer gets to 99% there is a big delay (copying the file from /tmp maybe?) and the speed starts to slow down and show incorrectly (perhaps taking an average over the last X seconds even though it has actually stopped).
It would also appear that rclone stops responding on ALL curl threads, because it will trigger a timeout error for all of them simultaneously:
rclone will then do a "low level retry", and it will always end up with the same result. One of the large files will take too long to finalize and cause a timeout on all active threads. I believe more threads will make this behavior even worse.
I found out that Nextcloud has a hard-coded 30 second timeout (for some silly reason), and it required changing a line in the code according to this post
Once I made this change Nextcloud stopped hanging up after the delay and it allowed all the files to continue correctly.
Is there some improvement rclone can make to not stop responding for so long as it finalizes a file - especially on all of the other threads that are not finishing?
As you have correctly diagnosed, the wrong transfer size is here due to errors.
Rclone will count all files it ended up deciding to transmit - including anything it needed to re-transmit.
So when errors occur, the total transfer can be larger than the actual data size. Usually it will be an unnoticeable difference - but in this case it is fairly serious errors it looks like.
You can use --timeout 1h (or some other time like 10m) to control when rclone times out connections on it's end of things. However - this will not really control anything on the server-side (which seems to be the problem here). If an option to control this exists it will usually be a setting in the remote or other interface that you use - and it looks like you found the right value in this case. --timeout can definitely be useful if you move huge files across mounts with write-cache though ect. so rclone does not give up waiting for the file to arrive.
I don't think it would really be possible for rclone to override that from it's core functions since what was going wrong was happening in a different layer of the system that wasn't directly under it's purview.
This delay is caused by nextcloud "finalising" the file. As you've discovered you can tweak the nextcloud timeouts to fix it. There isn't a lot rclone can do here unfortunately.
The error message ("Received error: cURL error 28: Operation timed out after 30000 milliseconds with 0 bytes received") you see is from nextcloud not rclone. Rclone doesn't use libcurl
Great!
I think this entirely a problem with nextcloud unfortunately. Until nextcloud returns 200 OK to the upload, rclone doesn't know whether it has been successful or not, so it can't go on to the next one.
Just to clarify - I updated the timeout on the remote server that I am copying files from - not on the local server that we are copying files to. So I do not think it is the local server having a timeout issue while finalizing a file - I think it is the remote server that is forcibly closing the connection because it has not heard anything from us (while we are finalizing the file).
Considering this, I can only think of two possibilities:
1 - my local Nextcloud pauses all WebDAV copying while it is finalizing a file on any of the threads, and thus rclone waits on it, and then the remote server hangs up on us.
2 - rclone pauses all webdav threads while waiting for confirmation that a single file has been copied, and thus the remote serve hangs up on us.
On the target (local) server I see a number of php-fpm processes roughly equivalent to the transfers and checkers. This leads me to believe that it is not Nextcloud that is hanging all threads (processes) while one finishes - but rather rclone - since I only see a single rclone process.
I may be very wrong in my assumptions and I mean no offense - I just want to understand better and help improve rclone for future users. If in the end it is caused by Nextcloud's WebDAV implementation I would not be surprised.
Rclone won't close the incoming stream until the outgoing stream has finished.
I don't think 2) should be happening unless there is a lock out of place in rclone. The webdav backend doesn't need any locking so I think that shouldn't be the case.
Not sure why nexcloud would do 1), again unless there is some central locking on something.
That is what I'd expect.
Rclone is running threads (or more accurately goroutines) internally, there will be one corresponding to each of those php-fpm processes. You can use the debug facilities if you want to see what goroutines are running.
No offense taken! I'd like to work out what is going on here too. I don't think we've got to the bottom of it yet!
I'll just note that timeouts while finalizing big files are a recurring theme with rclone with various providers - however it is normally the destination of the file that times out.
I changed it to copy 1 file at a time and the problem went away. I think I found the cause of this, and perhaps something that was making my other reported issues even worse.
My server arrangement is that I'm using a server with a 40 GB drive (30 GB free) with Nextcloud installed, but using external storage. At first I tried S3 external storage, but that had issues with modification dates. Now I'm using a Hetzner storage box that supports either WebDAV or CIFS. So really, the file transfer looks like this:
Local Storage -> Remote Nextcloud (WebDAV) -> rclone -> Local Nextcloud (WebDAV) -> External Storage (WebDAV/CIFS)
The /tmp directory grows with files from php-fpm as they are being downloaded by rclone. So with the files listed above, that's already 22 GB. When I was monitoring a single file being copied, I noticed that sometimes the /tmp files was 40% bigger than the file it was copying. It could be because it adds some extra buffer space, or because it is a bit slow to clear out old entries, or perhaps there is a secondary temporary file in use by Nextcloud or rclone that is further eating up space.
So whatever the cause is, it seems like it is having a storage "race condition" when it gets too many big files at one time.
I have a suggestion for rclone that would help, and not just in my case. Is it possible for rclone to "blend" the files it is sending? When I have 4 (or 8, 12, etc.) threads copying files, it will get stuck on 4 large files and max out my 10 MB/s network usage. This results in all files taking longer to finish, and spending more time in the /tmp directory. Also, when it gets to a folder with thousands of small files the speed will plummet due to the overhead of so many small files. Wouldn't it be better to balance it so that a few threads are maximizing bandwidth use (~90%?) while the other threads are taking care of all the small files instead of saving them until the end?
I think this would improve performance by reducing the strain on the /tmp directory and increasing the overall throughput of the sync.
This is very similar to a suggestion made by @thestigma
I've made part of the machinery for this with an --order-by flag. This needs a bit of co-operation with the upload threads to make sure some only pick biggest and some pick smallest.
Maybe it could be simplified to overload the existing --transfers to accept a list of characters?
Something like:
--transfers SSss
would mean 2 threads sorting by Large files first (SS) and 2 threads sorting by small files first (ss).
Some set flags like size, modified, created, name with both an upper and lower case to indicate descending or ascending sorting (SsMmCcNn) could make it pretty easy for the user to specify how many threads of each type they want.
I was thinking of something like --order-by size,mixed,50 which means order by size but with 50% of the threads on large and 50% on small or something like that with 50% being the default if not specified.
Yea, I suggested it to Nick a while back.
I think that in a large collection of various filesizes (especially if there are many trivial-size files) it could pretty drastically shorten the total transfer-time by balancing out the limited bandwidth with the limited amount of transfers that can be started pr second (on Gdrive and most other services that don't charge per-usage).
Because otherwise you risk maxing out one while the other resource is mostly idle, and then it may flip later. Transfering the largest files (at least one, preferably 2 at a time) along with the smallest would make a lot of sense there - because then the large file(s) will pretty much max bandwidth while all the small-file transfers will make sure that no transfer-limit quota goes to waste in the same timespace.
Nick recently implemented the --order-by flag , for exacmple --order-by size,asc
(order by size, ascending)
That also works for other criteria like names (alphabetical order).
But as far as I know at least there is no "mixed" mode yet.
I think that requires a little extra work as it needs to use 2 queues instead of 1 like all the other methods - if I remember correctly from Nick's explanation
That syntax would cover all the needs I can think of. Having the ratio adjustable would a nice bonus for sure I think I could live with a fixed ratio too if it turns out be difficult. I suspect the fact that is it mixed will matter a lot more than the spesific ratio.
The double ended queue is easy - I found a drop in for go's priority queue. It needs a little bit of plumbing so each transfer routine needs to be "coloured" large or small which isn't too hard either but I need to figure out how to get that info into the right place!
Here is a test version of --order-by which supports mixed so do --order-by size,mixed to have half the threads upload big files and half small. Add a percentage on the end to specify the percentage of small transfers.
Thanks Nick!
I've barely had time to check it, but I will see if I can produce some hard numbers that illustrate the benefit in a worst-case (or is that best-case?) scenario. Some tests on a non-ideal (very uniform size) mix of files would be interesting too to get some results for too just to verify that at worst this method will not be slower than the normal pseudo-random order. I expect it won't...
After it is well tested - it might even be considered candidate as a default setting and a general optimization. I can't think of anything that could break based on that, because the current default is fairly random, and as such no existing scripting should be relying on it to do the jobs in a spesific order.
Will let you know as soon as I have some testing reults to share