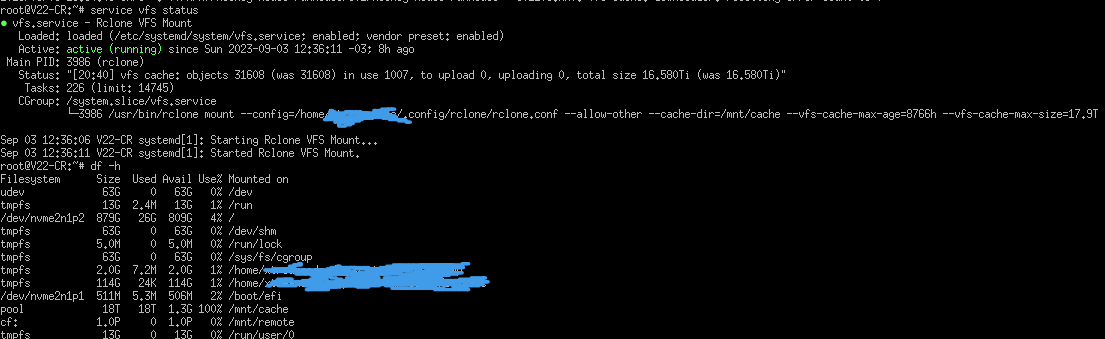
today I noticed many servers going offline and when digging I found out that despite having a 100 GB reserved from rclone from the actual disk size, rclone was still filling the entire disk to 100%
I always assumed that leaving 100 GB free was more than enough to prevent this issue and now I don't know what formula to calculate a safe free disk space.
It seems that rclone doesn't count /vfsMeta in the storage calculation and there is also a difference between what rclone reports in the log file to what ncdu,df reports
Right now rclone says total size is 16.486Ti but ncdu shows my /vfs folder at 17.1 Tib, so I assume there also left over files that weren't properly deleted by rclone
Calculating how much disk space is used is actually very hard!
You are right, rclone does not take account of the /vfsMeta. It also does not take account of any of the directories (which use a small amount of space).
What it does is add up the allocated blocks in each file in /vfs. That is an approximation though since sparse files can take up more space on the disk than rclone things due to disk block sizes and other things rclone doesn't know about.
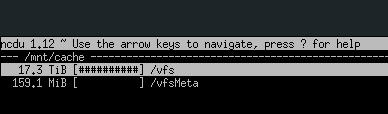
From your screenshots I see 3 estimates of the size used
vfs thinks: 16.58 TiB
df -h thinks: 18 TiB
ncdu thinks: 17.3 TiB
Note that ncdu doesn't measure the sparse files, so that might account for the difference between 16.58 and 17.3 TiB
We can see that there is about 0.2 TiB of vfsMeta
Can you try du -hs /vfs and du -hs /vfsMeta - du will account for the sparse sizes and should be more accurate.
Can you do a df -m /mnt/cache also - I'd like to see the numbers without rounding.
If you can get the what rclone thinks is free at the same time that would be useful too.
That is possible. The expiry time of the cache is the point these are removed. You could look for files which haven't been accessed for ages (find -atime) and delete them from the cache. Rclone will cope with that.
...
I suspect that this is a losing battle though... Maybe rclone should have a setting which says keep 100G free on this disk instead? I suspect that would work much better for you.
That's why I think instead of rclone trying to count the allocated blocks is it better to ask the system and trust what it says, either via ncdu/du/dh or whatever deeper system call you want to use
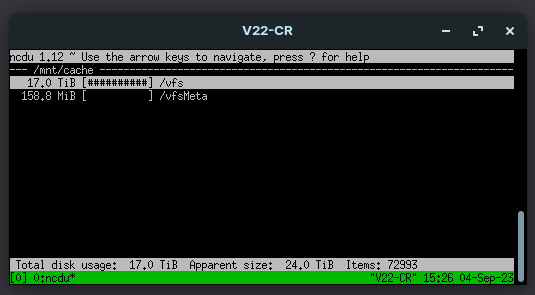
ncdu does measure sparse files, but it didn't show up in my screenshot :
Where total disk usage is the real disk usage, and apparent size is where what would be total size if files weren't sparse... I think
du -hs /mnt/cache/vfs && du -hs /mnt/cache/vfsMeta && df -m /mnt/cache && zfs list && zpool list && tail -f /opt/rclone.log
18T /mnt/cache/vfs
159M /mnt/cache/vfsMeta
Filesystem 1M-blocks Used Available Use% Mounted on
pool 18198850 17871840 327010 99% /mnt/cache
NAME USED AVAIL REFER MOUNTPOINT
pool 17.0T 319G 17.0T /mnt/cache
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
pool 17.4T 17.0T 402G - - 64% 97% 1.00x ONLINE -
2023/09/04 15:58:20 INFO : vfs cache: cleaned: objects 31229 (was 31229) in use 0, to upload 0, uploading 0, total size 16.327Ti (was 16.327Ti)
2023/09/04 15:59:20 INFO : vfs cache: cleaned: objects 31229 (was 31229) in use 0, to upload 0, uploading 0, total size 16.327Ti (was 16.327Ti)
zfs reservers a % of space from the pool so that's why it shows 402G free but only 319 G free, something I only discovered yesterday too
I don't enable access time on my zfs pool for performance reasons, but I do see the files still have access time different than modification and creation. Is rclone manually updating access time? Are you saying that rclone eviction doesn't work without access time enabled?
NAME PROPERTY VALUE SOURCE
pool atime off local
my flags: --cache-dir=/mnt/cache --vfs-cache-max-age=8766h --vfs-cache-max-size=17.1T --vfs-cache-mode=full
I think rclone should really improve this max size flag in multiple ways:
rely on the filesystem to check true disk space usage
If disk is full, instead of starting to throw a low of errors, start deleting old stuff before new writes fail because of disk space
be clear in the documentation if access time enabled is required to evict files from cache based on LRU
Thanks for the disk stats. It definitely looks like the vfs cache is seeing 16.3 TiB whereas du and df are seeing 17.0 TiB
Why?
This could be because of one or both of these.
rclone has lost track of stuff in the cache. This isn't impossible, but on startup rclone will clean the cache of stuff that shouldn't be there.
overheads not included in the calculation.
A previous version of VFS cache used to use atimes on the cache files but now-a-days this is stored in the corresponding vfsMeta file. So no, rclone does not use or set atimes anymore.
I can use the equivalent of du to find the actual disk usage of every file (and directory I guess) in the cache. I think I could make this work but it is still relying on rclone's adding up being the same as the filing systems adding up. This also doesn't account for lost files (which there shouldn't be, but hey, bugs!).
I could introduce a new flag say --vfs-cache-min-free 1G which would make sure that there is 1 GB free on the disk that --cache-dir is on. This is probably more accurate but is a new flag!
Rclone is supposed to do exactly that. Can you describe when you are getting the errors - are you only reading or are you writing too? What are the errors?
2023/09/03 22:19:40 INFO : FILEXX: vfs cache: downloader: error count now 30: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: write /mnt/cache/vfs/FILEXXX: no space left on device
2023/09/03 16:16:30 ERROR : FILEXX: vfs cache: failed to _ensure cache after retries vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: vfs reader: failed to write to cache file: write /mnt/cache/vfs/FILEXXX: no space left on device
2023/09/03 02:01:25 INFO : FILEXXX: vfs cache: downloader: error count now 1: vfs reader: failed to write to cache file: write /mnt/cache/vfs/FILEXXXX: no space left on device
2023/09/03 02:01:25 ERROR : FILEXXX(0xc0081de300): RWFileHandle.Release error: vfs cache item: failed to write metadata: open /mnt/cache/vfsMeta/FILEXXX: no space left on device
2023/09/03 06:50:27 ERROR : IO error: vfs cache item: failed to write metadata: open /mnt/cache/vfsMeta/FILEXXX: no space left on device
How can I find files that aren't supposed to be in the cache anymore if I don't have access time enabled ?
I'd love a flag to keep a minimum disk space free, but anyway I think rclone shouldn't let things get to that point. As soon as disk space is near maximum, rclone should start evicting files from cache so it never have issues of disk full.
I had users complaining about files not working, etc... In a disk/system where rclone is the only writer, should never have issues like this happening
Could have something like INFO: LOW DISK SPACE, EVICTING FILES FROM CACHE TILL IT REACHES MINIMUM
This could be checked every --vfs-cache-poll-interval
You can delete any files not in both (eg using rclone delete vfs --files-from-raw only-in-vfs)
Once you are confident with this you could certainly turn it into a little bash script!
I'd be interested to know if you find any and if you can work out how they got there? Eg
file renamed/removed via VFS
file renamed/removed on the source
other!
Either way we need to start reading the disk space...
Here is an attempt to add --vfs-cache-min-free-space to control the minimum space on the disk with the cache on it. You'd use it as --vfs-cache-min-free-space 1G say.
Note that this is only checked every --vfs-cache-poll-interval but if the disk gets full then having this value set (even to a very small number) should mean that rclone does the right thing.
If this works I may make this setting be on by default with a low value.
Anyway I have manually filled the disk, and started the rclone with new flag.... I tried to run with debug logs but it was just a endless stream of text but from what I can see it seems to be working!
Checking with df -h I saw disk space drop to ~300MB then a few moments later it grew to ~8GB. So I think rclone is deleting more than needed.
But at least the mount has been running for like 10 hours from now, and no users complained.
I also noticed that the number of objects dropped from 31229 to 25418 ! But rclone still only sees 16.330 but zfs list says 17.4 TB used.
So I think it works good enough to add as default flag because at least kept the mount operational but I still see errors about failed writes because of not enough disk space... I think I may increase --vfs-cache-poll-interval but I won't restart rclone right now
10% is a lot for big pools. Even zfs needs only 128 MB (I'm 99% sure of that lol) left to be able to delete files. Also lots of filesystems already have their own reserved disk space to avoid causing issues, so rclone doesn't need to build on top of that.... that's why my zfs pool didn't die with rclone filling the disk. And if someones reduce system reserved space they should know what they are doing!
I think maybe for me 1 GB is low because I have 10 gbps bandwidth and disks fast enough to write at that speeds... and the default poll check is every 1 min...so in 1 min rclone could write 75 GB of data, so maybe I should use 75 GB but at same time I don't want to waste so much space
I've seen issues with my cache device filling up when rclone restarts (or at least restarts after an unclean shutdown, such as a power outage).
I've never seen it otherwise, so it seemed to indicate to me that it didn't track existing data and assumed it could use it all and also didn't garbage collect data from previous run. my personal solution was to simply wipe cache device on every boot.
Yes but your use case is not typical IMO. Most people do not dedicate full disk for VFS cache and remaining free space is rather needed to keep OS running.
Whatever default value as long as this is configurable it can be always adjusted to individual requirements.
That means that there aren't any orphans and it is just the blocksize rounding that rclone isn't taking care of.
Not sure what happened there. If the disk usage (df) doesn't update instantly then rclone will get confused but I don't think filing systems are allowed to do that.
I think what I will do is merge the code as-is for the v1.64 release so people can experiment with it with the default off for safety - DONE! it will be in the latest beta in 15-30 minutes and released in v1.64