I don’t think that’s possible, cache and VFS work separate from eachother. VFS works directly on the gdrive mount while cache sits in between.
@Animosity022: I don’t know where it’s going wrong. I (for now) switched back to using cache. And disable Plexautoscan. What I’ve seen while debugging was that Plex had 2 shows which gave “unmatched leaves” this would make it refresh those shows EVERY time a scan happened. I.E: Plex autoscan gets a new scan request, it scans the new file / folder. Plex checks if there are any unmatched media and starts scanning those too. This happened on 6 servers on every scan (seasons are incoming so you can guess it will scan those 2 shows A LOT) that would be my guess why GDrive gave a ban.
I think you are hitting something along the lines of the vfs being too fast for you if you have 6 servers all doing the same thing at the same time. The cache is definitely slower in terms of getting chunks and requesting new ones as it has some waits in the code to check for chunks coming back.
If you check the API hits, adding a show and doing a scan should be pretty light.
It should expire the directory the new file is in. Ask for a directory listing. Plex should check all the files in said directory (cached from the listing). The new file should get analzyed (opens and closes the file a few times usually and does a mediainfo).
If you have that size of servers, I wonder if you have to limit even further to prevent those bursts. I’ve noticed if I have 6-7 streams going, I can easily get 3-5 requests per second when the stream starts as it’s so fast, it grabs as much as it can to buffer based on the transcoding settings.
I still don’t see how you are getting 24 banned by it as I did a fresh scan on a library last night and generated a lot of rate limits, but it just keeps going as it paces back and doesn’t try to keep downloading the files.
Here is my snap of the 403s (rate limits not the download exceed as that’s the “bad” 403).
I stayed under 1000 pretty easy too:
Yes that could be it maybe VFS is just too fast (which is good) To be honest I’m not yet convinced what the problem really was. Just the VFS being to fast when using 6 server and gdrive thinking “that’s not good” or the fact that every scan rescanned the 2 TVShows. I know that it didn’t download 10TB in the time between my last ban and the previous one think at most 300GB (50GB x 6) from scanning new media in the course of 2 days.
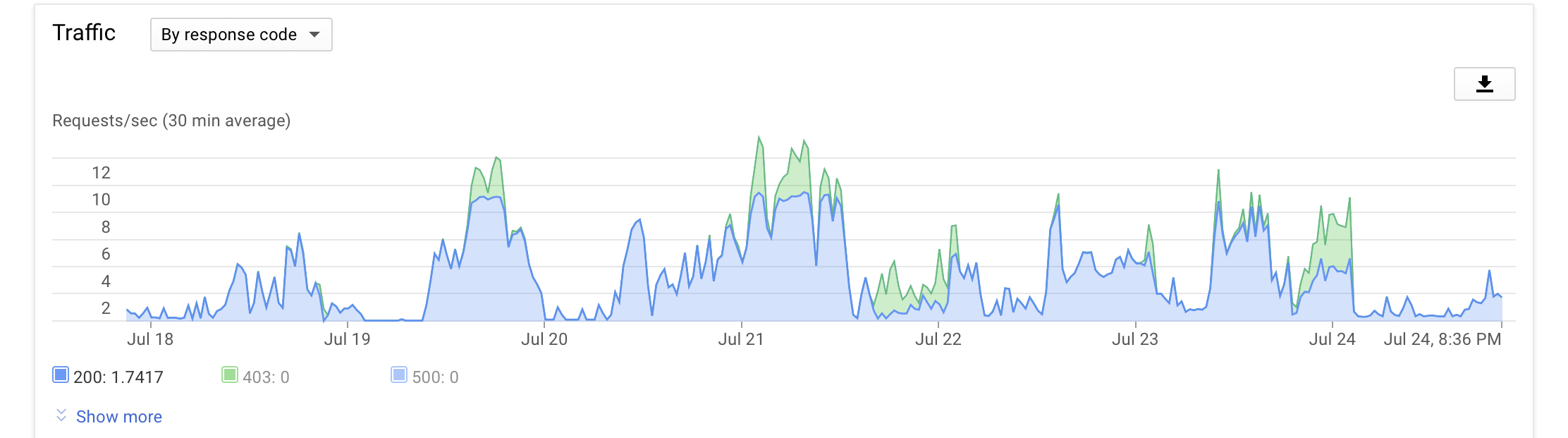
Here is my API traffic from the last week.
24th is traffic from one server scanning using cache. The big green errors were from the bans on 21st and 23/24th night. Others are just 403 pacer errors.
No 403 errors at the moment with cache, so maybe in my case being slower is better.
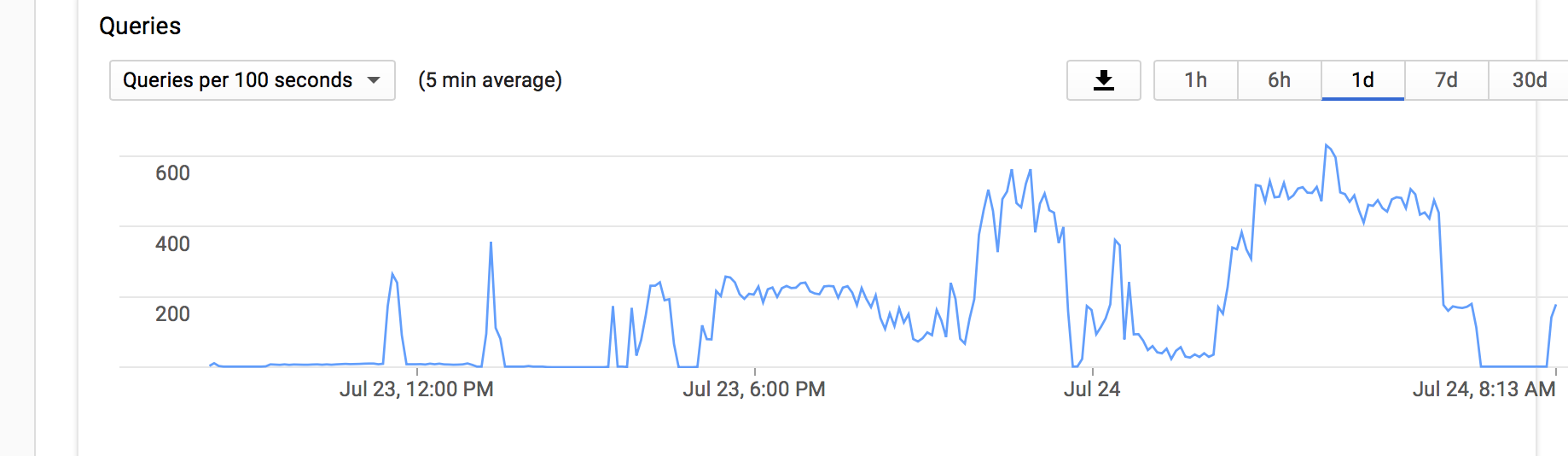
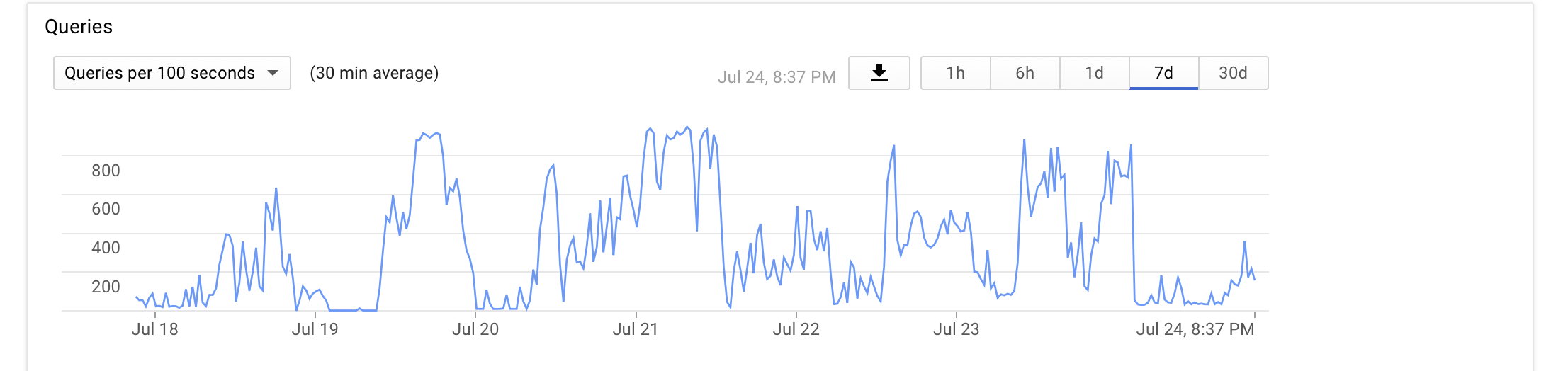
Here the overview of the Queries per 100seconds.
So basically, VFS reads as fast is it can and if you have a solid link and you are going to read quite a number of TPS across 6 servers.
If you peek at the cache code as I’m not a programmer by any means, there are some waits in there to see if chunks are delivered. The chunk delivery and how it threads out the multiple workers seems to me what takes it time to get the chunk back as it waits:
if !found {
// we're gonna give the workers a chance to pickup the chunk
// and retry a couple of times
for i := 0; i < r.cacheFs().opt.ReadRetries*8; i++ {
data, err = r.storage().GetChunk(r.cachedObject, chunkStart)
if err == nil {
found = true
break
}
fs.Debugf(r, "%v: chunk retry storage: %v", chunkStart, i)
time.Sleep(time.Millisecond * 500)
}
}
Those waits are a part of the delay in getting a chunk back as VFS just reads as quickly as possible. I’d surmise you won’t get 403s as the cache simply isn’t fast enough to produce them.
Have you guys ever tried requesting a quota increase from google. I did so a couple years back and I have 10,000 queries per user per 100 sec. I typically use around 2500/100 seconds when syncing my files. Just another option for you if you haven’t asked them to increase it yet. I got a little push back at first but a second email and they just increased the limit for me. I mentioned something along the lines that I only use one user and would like to open up the full quota.
What must i do to see this GSuite API Graphs? With my Account there are only the message “No Traffic” for 30 Days…
But i use my Plex all the day
Are you using your own credetials/API Key? If no, you won’t see them in the graphs. You’d have to create your own credentials and configure rclone to use them.
You can see it documented here:
https://rclone.org/drive/
Yes I asked for an increase and they not doing it at the moment. I guess because in the recent years there are more users who use gdrive with Plex. They told me they not increasing that quota for anyone anymore and made the advice to limit it and use exponential backoff.
To Use my Own Clint ID i must to setup with the own data?
Google Application Client Id - leave blank normally.
client_id>
Google Application Client Secret - leave blank normally.
client_secret>
with my own ID i have no access to my GSuite Drive…
The manual are not complete… were i must enter this Client ID and secret? There are 2 points that rclone config ask for something like that. In manual it say “normaly blank”
I think we’re confusing topics.
Are you using your own GSuite ? If so, you can go to:
https://console.cloud.google.com/
And generate your own API credentials to get access to your GDrive by following the:
https://rclone.org/drive/#making-your-own-client-id
If you don’t have your own, you are using the generic API keys for rclone which is shared by everyone using it so you may hit rate limits and such depending their use of the API key.
I´am an GSuite User… i´am not the Admin…
So your admin would have to create a key for you.
Okay, i find an working solution…
I have create an API Key with my own Google Account and make the Authentification with my GSuite User Account… No it works, an i can See anything in API Dashboard