Direct streaming was tested yesterday with —buffer-size=0, Movies started fast and worked great.
Getting these errors again; TVShows/Cops/Season 31/Cops - S31E03 - Keys to Success WEB-DL-1080p.mp4: ReadFileHandle.Read error: low level r
etry 10/10: couldn’t reopen file with offset and limit: open file failed: googleapi: Error 403: The download quota for this file has been e
xceeded., downloadQuotaExceeded
Cannot seem to find out what the downloadQuota for gdrive is, also it says for this file but noting loads at the moment.
EDIT: After thinking about it, VFS using the chunks will download more parts of the file while its accessing it, am i correct in thinking this will count toward the 1000 queries per 100 second quota? API console shows a spike to 1K and after that I’ve seen the errors.
EDIT2: Reading the other post about vfs-chunk-size, the API calls will be lessen when using vfs-chunk-size-limit. I’m confused.
Memory usage is currently "fine" for me. I was talking about wasted traffic by filling the buffer which is never used.
I tested ffprobe and mediainfo to see how much data they really read und how much buffered additionally.
It turns out, there is no difference in traffic between --buffer-size 4M and --buffer-size 64M. Only --buffer-size 0 makes a real difference.
With --buffer-size >= 4M a mediainfo call will waste around 7-10 MB per file and ffprobe only 3-5 MB on an 1Gbit/s connection.
So its not worth to reduce the buffer size to save on traffic.
Sadly, there is no official download quota. It is possible that there are different kinds of "bans".
At one time during a downloadQuotaExceeded limit, I was able do still download smaller files and even parts of larger files using the Range header. Since then i never encountered the downloadQuotaExceeded error again to verify this.
Yes these will count towards your quota. They will be listed as drive.files.get in the API console.
When only --vfs-chunk-size x is set, the chunks will always have a fixed size and every x bytes a new drive.files.get request will be sent.
If --vfs-chunk-size-limit y is also set the chunk size will be doubled after each chunk until y bytes is reached. This will reduce the number of drive.files.get requests.
You can set --vfs-chunk-size-limit off to "disable" the limit which means unlimited growth.
1 Like
Thanks for the info, don’t know yet what the problem is (beside the 1000 request per 100 second quota) had 4 servers adding a media file to Plex so plex was scanning one season folder and analyzing the newly added episode. This worked fine when I was testing with 3 servers. I’ll test again after the ban is lifted. Also will test with cache to compare.
Well the ban was lifted 6 hours ago so that’s good. Still cannot find the overview of the 1000 Queries per 100 seconds in API overview.
I tested my servers and with vfs-chunks I see higher queries than with cache, same amount of media was scanned.
@ncw: Is it possible to limit the speed of the requests rclone make to lower the 1000 Queries per 100 seconds?
It's in this window:
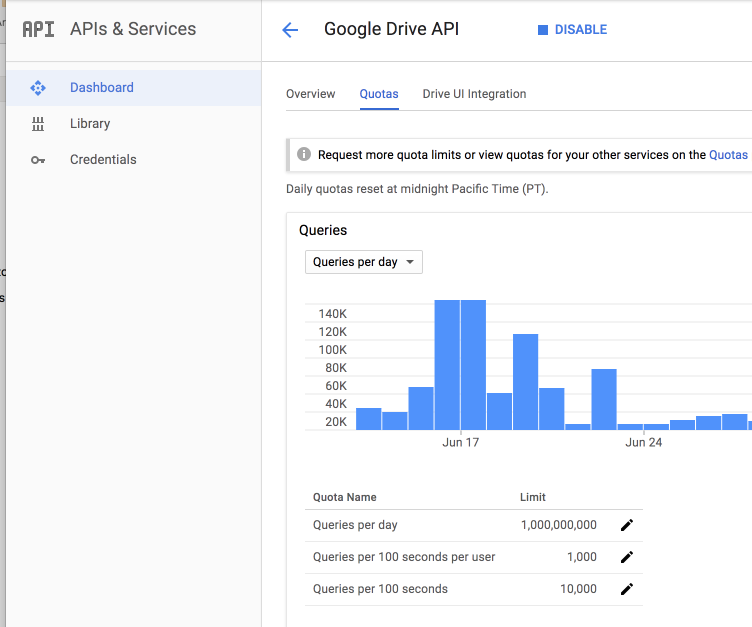
You can already limit your queries per second:
--tpslimit float Limit HTTP transactions per second to this.
--tpslimit-burst int Max burst of transactions for --tpslimit. (default 1)
Yes, I’m monitoring that option now
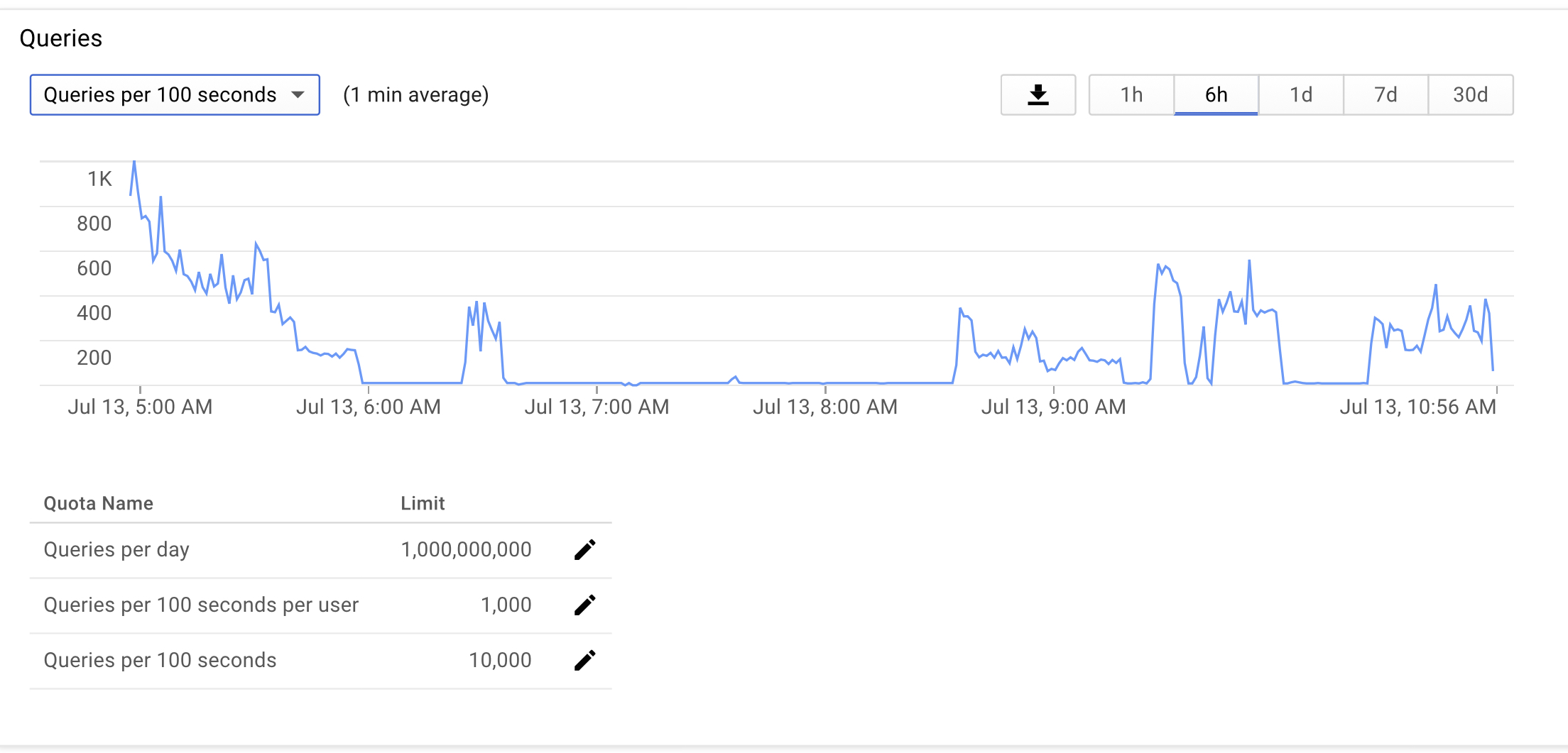
But that’s the one with the 10K quota. Anyway i’ll just try and keep it as low as possible. 3 of the server had “loudness analyzation” switched on so you can see the end of the spike at 5:00 AM in the graph. No bans though. Maybe just a fluke yesterday.
@Animosity022: Interesting, I’ve set my test server back to use vfs instead of cache with those two added.
tps-limit 2.5 and burst at 10.
Does VFS have support for hardlinks by chance? Sonarr and Radarr have this function where it can create a hardlink over a copy instead. It would be cool if this kind of thing worked with rclone since right now it has to copy over the file to exist on the drive twice with the writes function, which can take a while for slow drives, then upload it after it’s finished copying. I was thinking if the hardlink was created in the tmp writes folder and uploaded, would it become the actual original file on the rclone mount? That could save a lot of time.
Sadly, you can’t hard link across different file systems. You’d have to get creative and link the the tmp area underneath and bypass fuse somehow and write directly as a hard link needs the same file system.
So one week no problems and the dreaded “error 403: download quota for this file has been exceeded. downloadQuotaExceeded” I’m starting to suspect my download server which is downloading, writing and reading (radarr sonarr x2) a lot of data. I didn’t add the http limiter to that server yet as it is using cache for writing and didn’t think it could be that. Last time the server was also busy downloading.
Got 6 VPS units now who do plex scans at random intervals when new media is added and that worked well the last week.
Contacted google last week and they couldn’t provide me with info about the above error. Just the “gdrive has undocumented quota’s in place which we cannot publish”
You could setup different API keys for each one to see if one in particular is causing a problem. You could also do much bigger chunks to reduce the API hits per second as well. I’ve been testing 64M and that does make a difference.
Also, the directory layout matters to and you can use much longer dir-cache-time.
What’s your quota window look like when you got the 403s?
Yes switched my servers to other keys already so I can see what’s doing what. Not hitting the daily API quota, not the 10000 per 100sec quota (max on the graph today was 1K) normally peaks around 800. If I’m hitting the 1000 per 100sec per user, that’s possible, but I would presume I would get an other error.
Edit: (thought about it and removed some nonsense)
Can’t be the upload as I’m still downloading and uploading. So I’m leaning to to many API hits per 100sec per user. 2 servers where not using tpslimit so that could be the culprit. Or I’m hitting a magic “not going to publish” google limit 
Hmm. If you are hitting the 750GB upload limit, that’s easy enough to limit/monitor.
If you are hitting the 403 download rate limit though, that one seems very odd to me as you’d get some 403 ‘back off’ type errors if you were doing too many per 100 seconds or whatnot, but that shouldn’t ban you. I get many 403s depending on my initial scans and how I configure things but those just ask you to ‘slow down’.
The downloaded too much worries as me as that tends to me to think something is configured off somewhere on one of the hosts if you are hitting that ban.
You might also want to do some math and limit your max transactions per 100 by taking into account all 6 VPS machines so throttle a little more.
My math for me is just for a single host ensuring I don’t hit the quotas.
Edited my post cause it’s not the upload (still uploading) graph of the last day showed lots of 403 errors but rclone not giving errors (retrying and succeeding I guess)
tps limit is at 2.5 with 10 burst for ALL clients should be a nice average for normal days (lots of downloads now so lots of scans at the moment, random times so spread) i’ll see how it goes tomorrow and maybe lower the tps-limit to be at the safe side.
Yep, with INFO configured a retry (403) and it working, it will not print a message in the log.
Yep! And I guess a retry counts as a API hit? I looked up in rclone wiki but can’t find the default retry times (and how to change it)
It’s:
--retries int Retry operations this many times if they fail (default 3)
--retries-sleep duration Interval between retrying operations if they fail, e.g 500ms, 60s, 5m. (0 to disable)Well don’t know what the issue is, I seem to be hitting an undocumented gdrive limit as my clients are limited to 5 tps and still I’m got the error. It seems to be connected to the new files which are being scanned by 6 servers. Each file will be accessed multiple times times 6. Already gave plex_autoscan a random scan delay to spread the load, but it seems like there is a limit on how many times a file can be accessed / downloaded. I’ve temporarily disabled plex_autoupdate and will test again after the ban is lifted.
There could be another limit as the only we can see i the 1000 per 100 seconds, which is why I suggested 5.
Quick tangentially linked question: are we moving towards a situation where VFS and cache backends work hand in hand? Being able to have a safer upload method when using VFS appeals for all the perks VFS seems to give for reading.