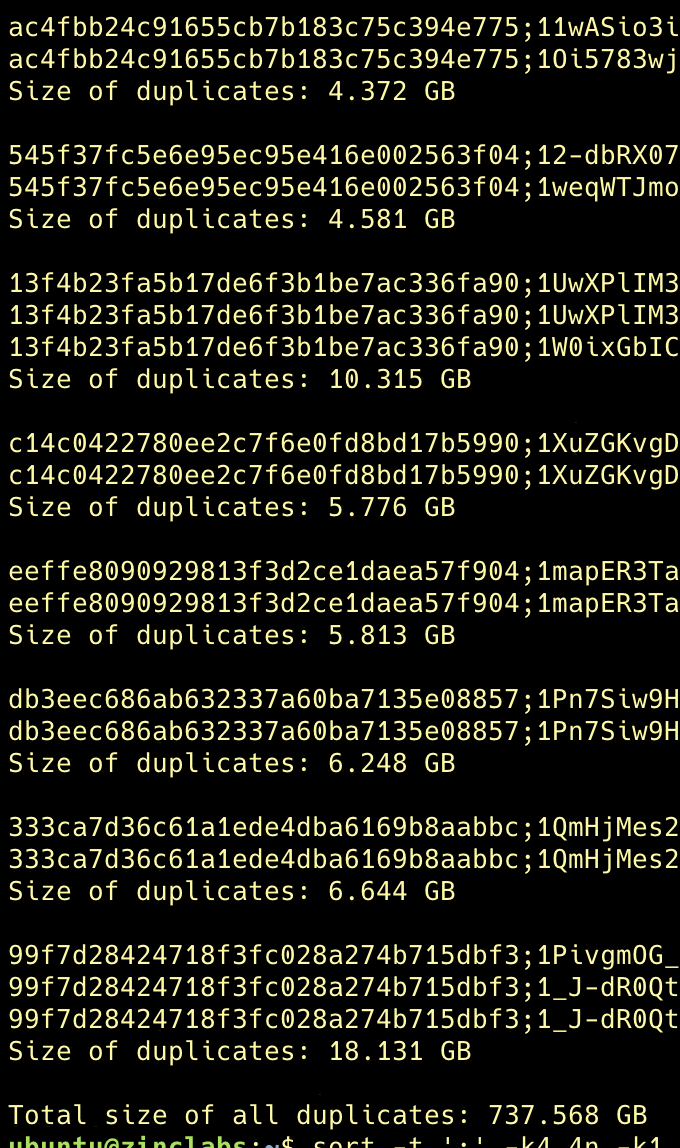
I'm trying to dedupe my Google Drive. The best way I've found is by using
rclone lsf drive: --files-only --fast-list --checkers 200 --format hipst --hash MD5 -R | tee items.txt
and then finding lines that have matching hash & size. Works pretty well.
However, I notice that there are 2 scenarios:
(a) multiple items have the same hash, but different ids
(b) multiple items have the same hash AND same id, but different paths
Example:
9ff7d28424708f3fc028a274b715dbf3;1PxabcOG_Tsx-5DdmtHpGjVOdagLuWFTW;SHELLY/SHK/COMPLETED VIDEOS/CANA DE AZUCAR/MEDIA/Day1/INTERVIEW/C0023.MP4;9733751771;2016-02-05 05:53:16
9ff7d28424708f3fc028a274b715dbf3;1_J-dR0QtTBYabcTh4jn_x6dfp0Z-JaBK;SHELLY/COCINA/CanaDeAzucar/Day1/INTERVIEW/C0023.MP4;9733751771;2019-06-23 07:36:10
9ff7d28424708f3fc028a274b715dbf3;1_J-dR0QtTBYabcTh4jn_x6dfp0Z-JaBK;archive/disks2019/media/MEDIA/COCINA/CanaDeAzucar/Day1/INTERVIEW/C0023.MP4;9733751771;2019-06-23 07:36:10
All 3 have same hash and size; 2 also have same id; all have different path.
My question is: in scenario (b) is there 1 original and the rest are aliases – and therefore deleting the dupes would not save any space?
What about in (a) – if the id is different does it mean that deleting the "copies" would save space?
And if anyone is interested, this script will take the output of the above and
- find dupes (where id & size both match)
- organize them in groups
- calculate the humanized 'dupe' space usage (for now ignoring my question above!)
- give a grand total of wasted space
- save to a file
dupes.txt
sort -t ';' -k4,4n -k1,1 lsf.txt | awk -F ';' '
function humanize(bytes) {
suffix = "B";
if (bytes >= 1024) { bytes /= 1024; suffix = "KiB"; }
if (bytes >= 1024) { bytes /= 1024; suffix = "MiB"; }
if (bytes >= 1024) { bytes /= 1024; suffix = "GiB"; }
return sprintf("%.3f %s", bytes, suffix);
}
{
group_key = $4 ";" $1;
if (group_key == prev) {
if (seen[group_key] == 1) {
print prev_line;
}
print;
if (seen[group_key] > 0) { # calculate the size of duplicates, exclude the first occurrence
size_of_duplicates += $4;
}
seen[group_key]++;
} else {
if (seen[prev] > 1) { # Only print for duplicates
print "Size of duplicates: " humanize(size_of_duplicates);
total_dupes_size += size_of_duplicates;
size_of_duplicates = 0; # reset for the next group
print "";
}
seen[group_key] = 1;
prev_line = $0;
group_size = $4;
size_of_duplicates = 0; # Reset duplicates size for the new group
}
prev = group_key;
}
END {
if (seen[prev] > 1) {
print "Size of duplicates: " humanize(size_of_duplicates);
total_dupes_size += size_of_duplicates;
print "";
}
print "Total size of all duplicates: " humanize(total_dupes_size);
}' | tee dupes.txt
Example: