Use case:
The setup containing pretty fast network connection, amount of RAM and comparably low IOPS disk system on rotational HDDs (but fine in bandwidth terms).
To utilize network I have to increase amount of transfers or enable multi-threaded downloads while both of them causes slower IO on rotational HDDs which causes slower total transfer speed.
Proposal:
Dedicate file write into the queue with specified amount of writers and configurable write block size.
This will allow to utilize rotational HDD bandwidth with lower IOPS rate such as network connection with RAM for that queue.
I'm not sure I understand your proposal - can you elaborate?
Note that --check-first is useful for HDDs also.
Sure,
--check-first allows to separate reading HDD access pattern (on verifying checksums) from writing HDD access pattern (on actual data copying) which is a good way to increase performance and it works perfect thanks for that!
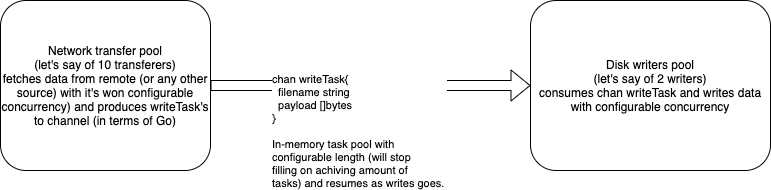
My proposal is to add a "writer task queue" between network transfer and actual disk writer to make them asynchronous, allow sequential write pattern (with multiple network transfers) which the fastest possible on rotational HDDs and make them configurable for concurrency independently.
As a side effect this construction will utilize more memory for storing data in such queue but it could be limited in terms of data size and chan length to avoid out of memory scenario.
I'm not quite sure it will help since the issue is not only serialising writes but also limit their concurrency, AFAICS --buffer helps on huge files in the scenario above but on small files for better network utilisation I have to set higher concurrency for transfers with --transfers=64 (actual value for 128M files I'm using with macOS sparsebundle images, btw) and since transfer is a synchronous operation it could cause up to 64 simultaneous writes to local disk. While on SSDs it works fine (I've already checked) on rotational drives it's dramatically slow.
Btw, I have a kinda workaround for that which helps a bit: to set --buffer-size=<higher value for file size> --multi-thread-cutoff=<lower value than file size> --multi-thread-streams=<something about 4-6-8> to increase RAM usage for file construction before write.
I could play a bit with local backend but I'm almost sure it's not about implementation only it's mainly about architecture and separating writes from reads.
I'm not quite understand how mutex could help here but please give me some time to look at the code of rclone, since I haven't checked out how it's implemented yet starting from architecture proposal based on observable rclone behaviour.