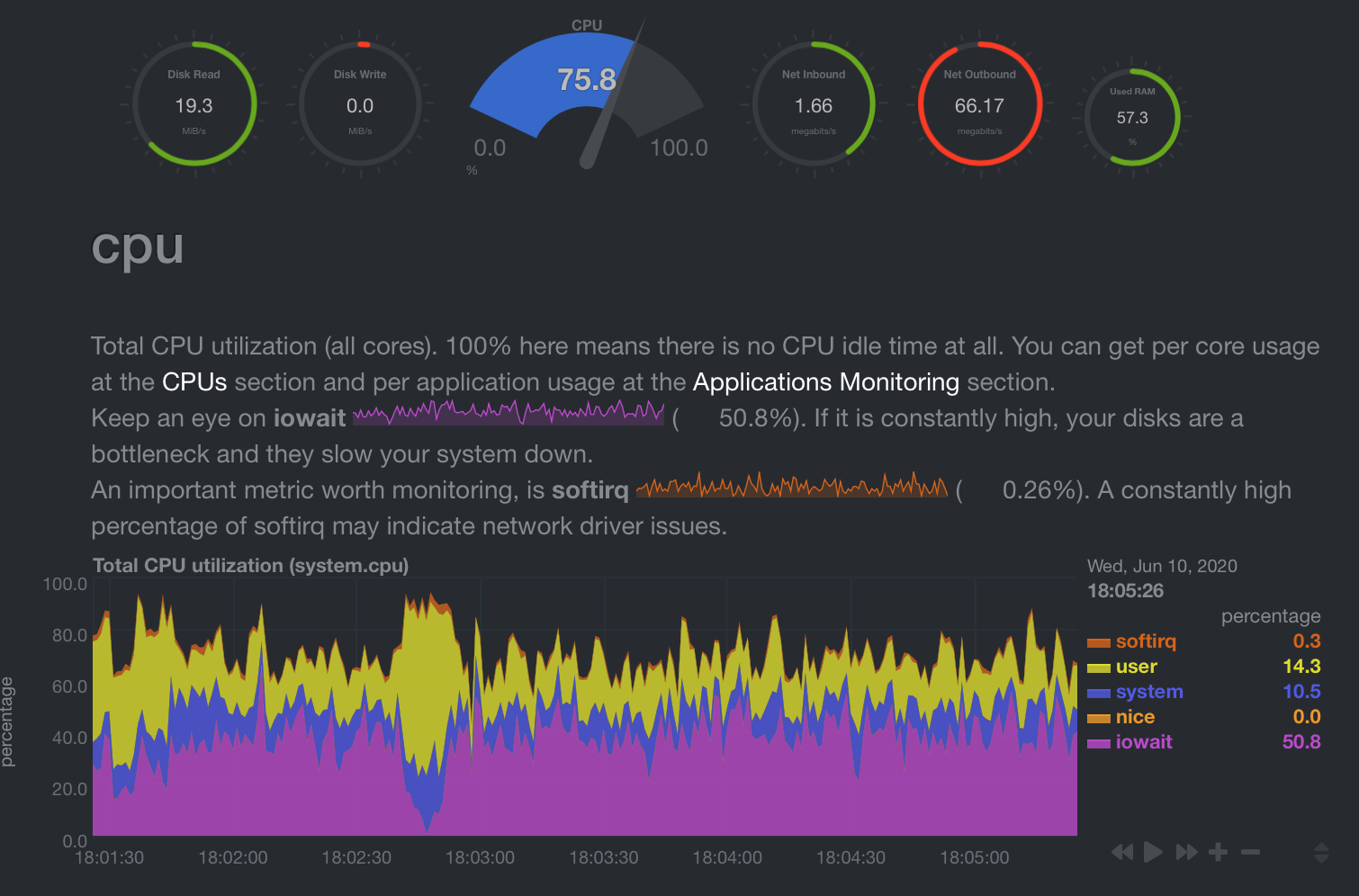
IOWait is happening because multiple files are being read from the disk at the same time, which is reducing throughput (19MB/s instead of 110-120MB/s) and causing delays.
Earlier versions of rclone did sync_reads, which means the OS read say parts 1 2 3 4 in order and got returned back in order parts 1 2 3 4.
New kernel versions have aync reads available along with fuse so that means you can ask for 1 2 3 4 and you may get back 1 3 2 4 and rclone puts it back together.
There isn't a yes/no answer to IOWait as it depends on what's is happening on the system and what the reads are doing coming in.
A database, for example, uses async reads as it does many, many requests at the same time so it has to service things as quickly as possible.
If a copy a file from a to b, it's "probably" better to do that sync and read in order as I'm sequentially reading a file. If I expand that to reading 10 files at a time with a program, maybe async is better or maybe it isn't as it has to be tested.
My use case is normally streaming media and that works pretty well for my use so I currently use sync_reads. At some point, I'll go back and test out async and it really should be better but I personally haven't done that yet.
If you can describe you actual use case and setup and share a log, we can take a look and provide feedback. These questions are not simple yes/no type things and more info is needed.