Hi! I'd be interested in helping improve the stats calculation for multipart uploads.
Right now, it seems to calculate the speed based on how long it took to read the parts into memory, rather than how fast it's actually uploading to a remote (I'm specifically using S3-compatible storage, but I assume this applies to all multipart-compatible remotes.) For large multipart sizes (eg. 100M), this can cause the stats calculation to be wildly inaccurate, jumping to 100Mi/sec at first, and then dropping to zero as it waits for the parts to upload.
Is this feasible? If so, I would be happy to work on this, and would love suggestions on where to start
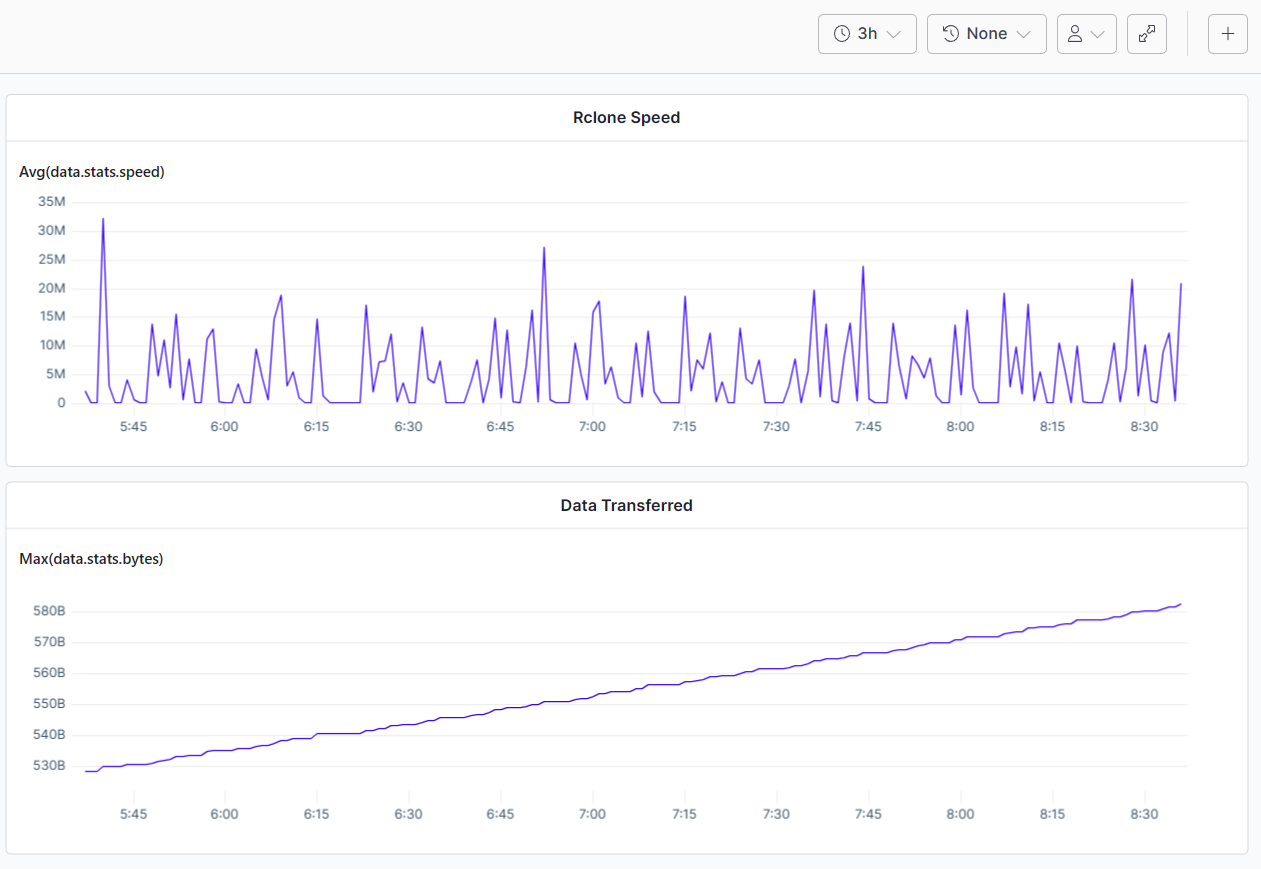
Here's an example: I have a large file uploading with 10x concurrency with fairly large part sizes (around 500M because Scaleway has a 1000 part limit.) I've been monitoring the upload rate via nload (on linux), and it's very consistently transferring at 41Mbps. But the stats drop to almost zero because it takes so long for each part to upload.
Here's a graph of the last 3 hours from rclone json log output for stats where we can see the pattern of constantly dropping to zero due to waiting on multipart, and then jumping very high (despite it very consistently uploading at 40Mbps according to nload, meaning that it's not actually hitting 200Mbps+)
This will change the way the stats report - probably for the worse. However it should improve your throughput as it will read multiple source blocks in parallel.
Note that you'll need to set --multi-thread-streams to set the concurrency of the upload.
I haven't figured out exactly how to fix the stats reporting as rclone reads the source chunk in its entirety before starting the upload. It needs to do this to calculate the MD5 which it needs to send along with the chunk.
I think the S3 library also reads the data more than once but doesn't tell rclone about that so if we just instrument the reads then rclone will see the data being read twice.
What I could do is
count the data as read when the consumer reads it
if the consumer rewinds the stream then uncount the data
This would cause the stats to jump up while the hash was calculated then jump back (this would be quite quick) then it would count up properly while the data was being transferred over the net.
This is probably the most accurate scheme but I don't know whether the jumping up and down at the start would confuse people utterly or not!
Or I could implement a heuristic which said only start counting the stats after the stream has been rewound N times where N will need to be work out for each backend individually.
I've merged the multithread code to master now which means it will be in the latest beta in 15-30 minutes and released in v1.64
The backends do do things to help the stats calculation along.
I'm going to have an experiment with that later today and see how it works.
That is a good question and one I'm going to have to explain in the docs. Maybe the options need simplifying here.
Here is what has happened
Old rclone
if size below --s3-upload-cutoff (default 200M) do single part upload
otherwise do multipart upload using --s3-concurrency to set the concurrency used by the uploader.
New rclone
if size below --s3-upload-cutoff (default 200M) do single part upload
if size below --multi-thread-cutoff (default 256M) do multipart upload using --s3-concurrency to set the concurrency used by the uploader.
otherwise do multipart upload using --multi-thread-streams to set the concurrency
Now that I've written that out it looks needlessly confusing.
I guess the options for rationalising it are
use --s3-concurrency instead of --multi-thread-streams to set the concurrency. This means each backend can set different concurrency levels.
this is backwards compatible with people's config
it means --multi-thread-streams will no longer be used (or maybe the default for backends that don't care)
this will require changing the ChunkWriter interface
use --multi-thread-streams to set the concurrency everywhere. Neat, but doesn't allow different concurrency settings for different backends.
this is not backwards compatible with people's config
this will require reading the value of --multi-thread-streams in the backend (easy)
use a hybrid - use the maximum of --s3-concurrency and --multi-thread-streams - this allows individual control for each backend but has a global override
this is backwards compatible with people's config
it means --multi-thread-streams still does something useful
this will require changing the ChunkWriter interface
Hmm, I've posted that on the issue for the other developers to comment, but I'd be interested in your feedback too.
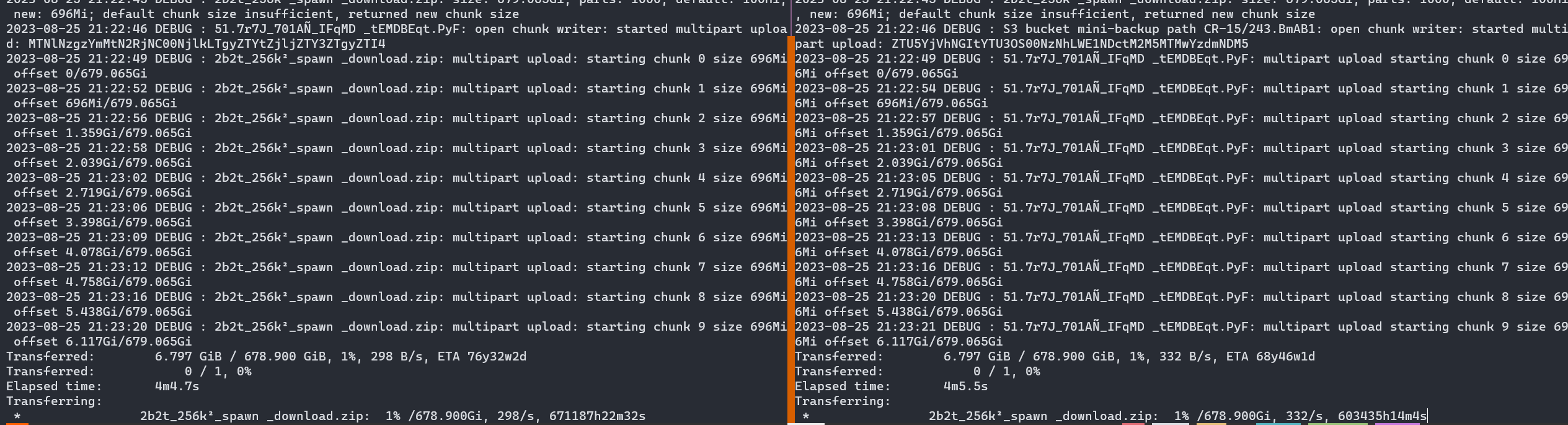
Hmmm, I ran this side by side with normal rclone using 696MB parts (the min size for a file this size transferring to Scaleway object storage which is limited to 1000 parts). As far as I can tell, they are both doing the same thing: They started off showing 300+ MB/sec, and then trickled down to zero at the same rate:
If I try it with v1.63.0 then I see the effect you are seeing with a very high peak then gradual decay down to nothing.
I suspect that you tried an rclone version without the fix somehow. The latest beta at the time of writing is v1.64.0-beta.7291.b95bda1e9 and this definitely has the fix in - can you give that a try?
I figured out what happened! I have a crypt overlay on the S3 bucket I'm using, which doesn't seem to apply the fix. But using an S3 remote directly shows accurate speeds!
Thank you for your patience - that's definitely my bad for not mentioning that before