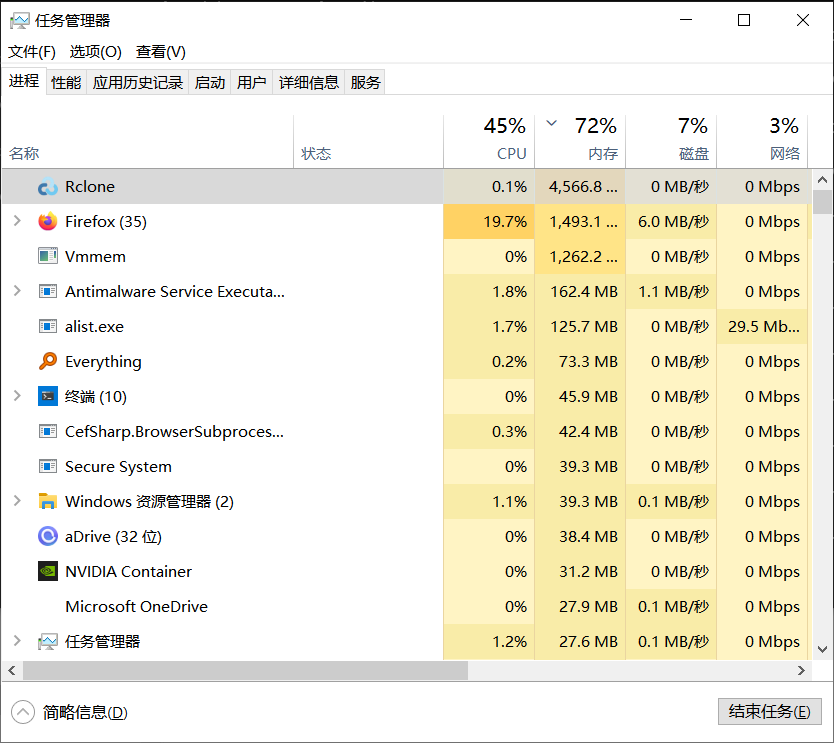
Huge memory usage (>10GB) when upload a single large file (16GB) in WebDAV backend (Aliyun+Alist). Crash out of memory.
I tried --cache-db-purge and wait for a week for the cache to be expired but still didn't work.
Run the command 'rclone version' and share the full output of the command.
rclone v1.65.0
os/version: Microsoft Windows 10 Pro 22H2 (64 bit)
os/kernel: 10.0.19045.3693 (x86_64)
os/type: windows
os/arch: amd64
go/version: go1.21.4
go/linking: static
go/tags: cmount
Which cloud storage system are you using? (eg Google Drive)
Aliyun+Alist (tool for translating aliyun API to WebDAV)
The command you were trying to run (eg rclone copy /tmp remote:tmp)
rclone mount ali:/ J: --no-modtime --vfs-cache-mode full --vfs-cache-max-age 100h --vfs-cache-max-size 1G --vfs-disk-space-total-size 6T
Previously I was using: (I changed cache-size from 16G to 1G as above, neither could work)
rclone mount ali:/ J: --no-modtime --vfs-cache-mode full --vfs-cache-max-age 100h --vfs-cache-max-size 16G --vfs-disk-space-total-size 6T
The rclone config contents with secrets removed.
[ali]
type = webdav
url = http://0.0.0.0:5244/dav/ali
vendor = sharepoint-ntlm
user = admin
pass = *** ENCRYPTED ***
Does that mean the memory is only subject to the complexity of directory structure?
Actually I have a crypt remote inside the root folder which is related to this problem. (This problem happened originally inside the crypt one. I moved it to uncrypt remote later to simplify the question.) I belive the uncrypt remote (we are talking about) has the same amount of files as the crypt one, acording to the crypting method.
I made a test, copying 4G file into the remote (no matter crypt or not), and observed the same symptom. The memory is correlated with the file size. (4~5G)
The problem is I cannot make the simpler uncrypted remote pass the first minute because of crash out of memory:(
Is there any command except --cache-db-purge that can completely reset the cache? I have already given up my files in that cache.
I'm trying to borrow an another windows laptop (I only have a macbook around here), and another WebDAV backend server to replicate this. It may take a long time to reply, appologize.
Confirmed. Changing vendor from sharepoint-ntlm to other indeed solved my problem. Thanks so much for your support.
That is weird. I remember I did select other for the vendor during config. And when I'm struggling with my (weak) windows NAS with rclone 1.65 installed to reproduce, the config shows other correctly... Anyway, its maybe an old version's issue.