Why I should care about API calls as long I'm under my quota, which is very generous btw? I rather increase performance even if it does more API calls.
You need to balance API calls quota vs performance.
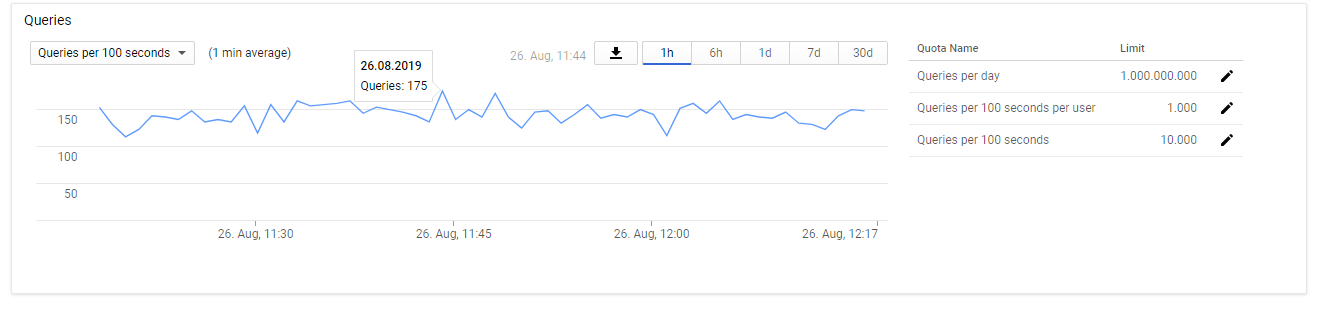
By default, you only get roughly 10 transactions per second via the google API.
So you really want the sweet spot of making enough calls to get the best performance, but not too many calls to get rate limited and forced to back off.
In general, if you are playing a file in Plex and can make 1000 API calls to play a file or play the same file with 10,000 API calls. What is better? As a general statement, less API calls per second to produce the same result is less taxing to do.
buffer-size is the amount of memory per file that is used when a file is opened and read sequentially. Once the file is closed, the buffer is dropped and isn't reused. I've toyed around with many buffer sizes as it really only impacts "Direct Playing" in Plex.
In theory, a big buffer size would provide some help if you had some latency in getting the next set of data assuming that Plex keeps the file open and is reading sequentially. I've never really gone down and fully tested this to how effective it is.
Is there a way to have some kind of progressive chunk size? So we can start with 10 MB and go bigger over time if it's a sequential read?
I don't have any buffering issues, even with high bit rate usage with my current settings and my RAM usage is really minimal with ~40 open files on the mount
If you have an initial read request of 128M and the read continues to go sequentially, it starts to request larger sizes by going to 256M / 512M / etc.
There really isn't a concept of a chunk tough. It's requests a piece of data and the buffer-size is where the data stays.