Assuming that the setup is working as it should, unnecessary advanced scanning that is not suitable to cloud is disabled, and that there isn't any weird issue of rapidly opening and closing files going on...
Then API will basically be a non issue.
With default settings you will need 1 API call to request a 128MB chunk to read. This could be set even higher if needed, but even on a very high bitrate stream this means API calls will be quite infrequent to serve one viewer.
You can (with default quota) make 1000 requests pr 100 seconds, or 10/sec on average during sustained load in other words. That should be theoretically sufficient to serve dozens of users. You will likely be bandwidth limited before this becomes an issue.
You effectively have no cap on the amount of requests pr day. You can do 10/sec 24/7 for 864 000 API calls in a day. 10TB download/day , 750GB upload/day.
API limits mostly come into play when dealing with accessing loads of files, which for Plex mostly means some of the more in-depth scans that actually open each file to make thumbnails, featch stream-data ect. These should therefore not be run automatically but only manually triggered (and preferably not often) if you have a large library. It's the sort of thing you do on a maintenance day when the system will not be used much
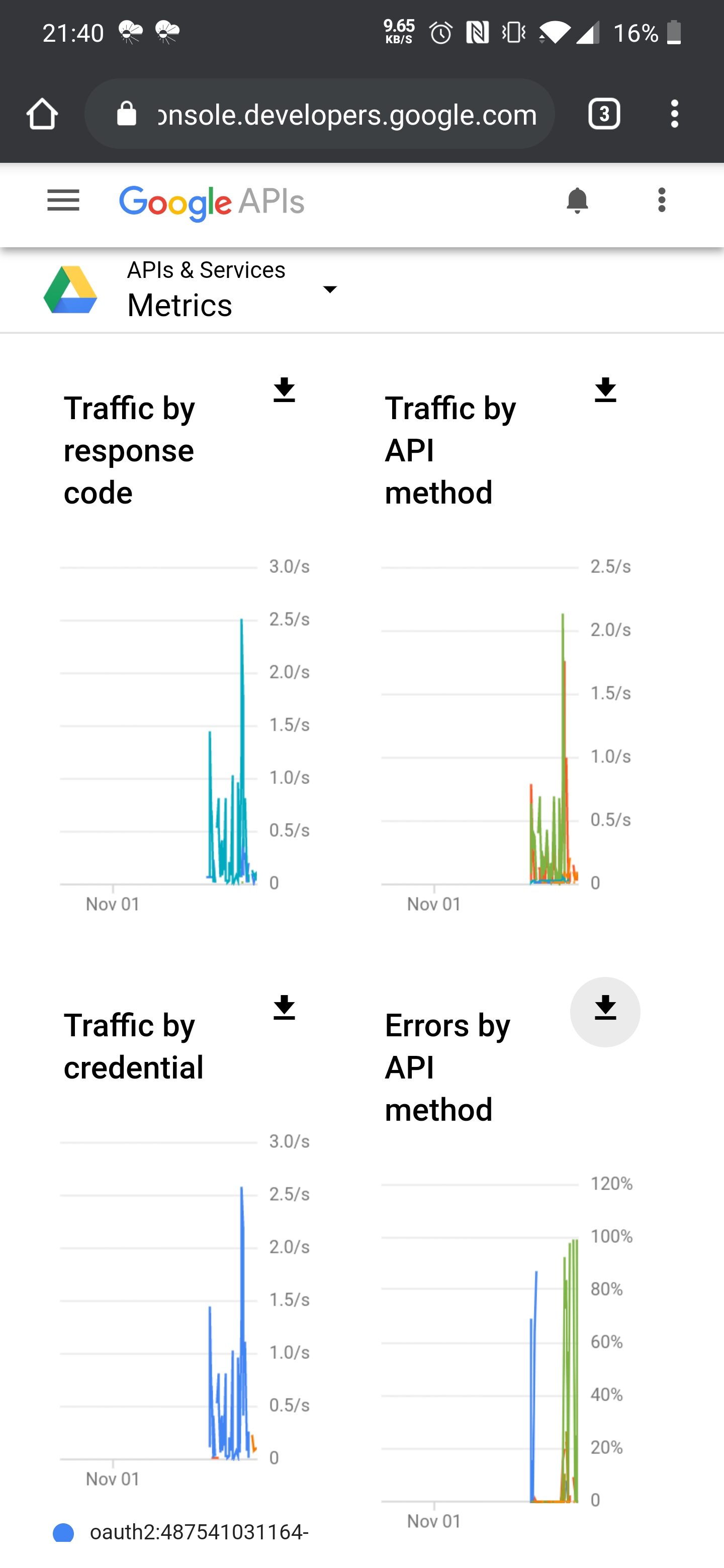
If you still are not convinced, you can go take a look at the API yourself: https://console.developers.google.com/apis/api/drive.googleapis.com
On that page you will get a nice graph and statistics about API calls, the percentage of errors (some small % is normal) and more.
Let me also clarify you can not get "banned" from the API from over-requesting. You can only run into the 1000 pr 100sec quota. If you spam too many requests you will just get a 403 error back and rclone will have to re-request in a second or two later (ie. it deals with it automatically).
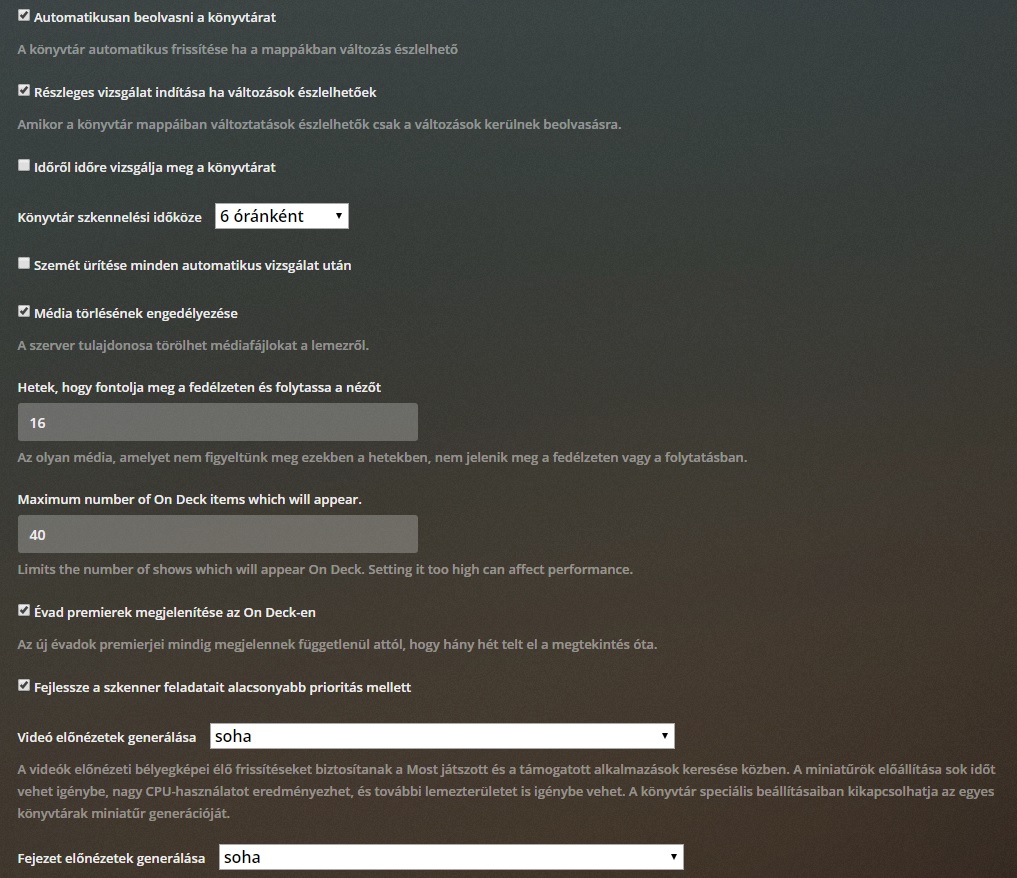
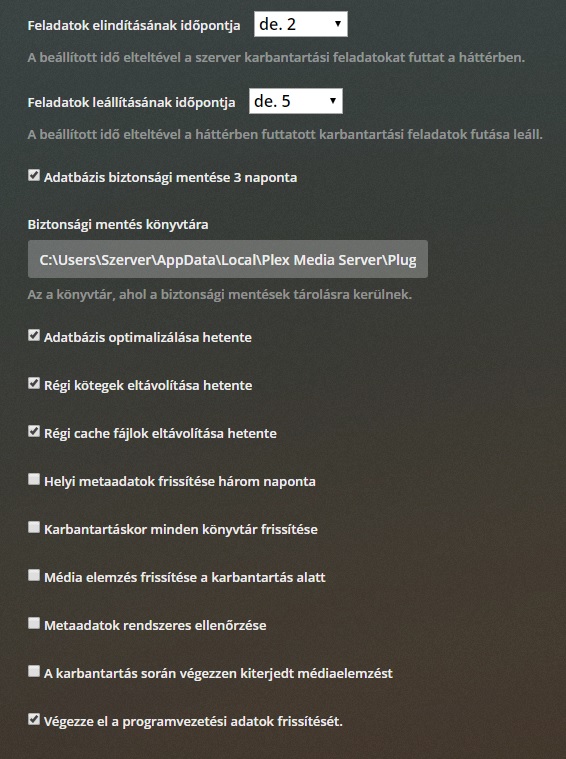
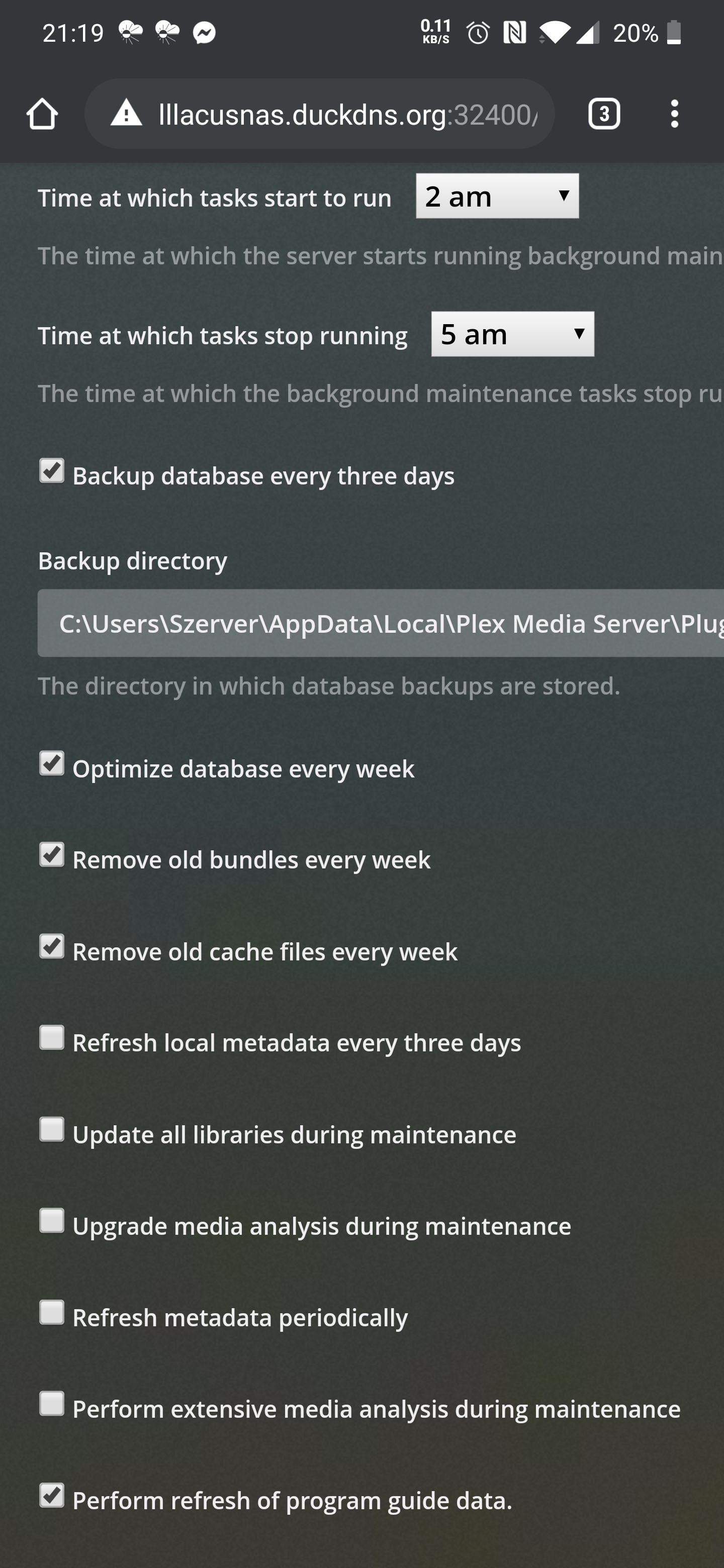
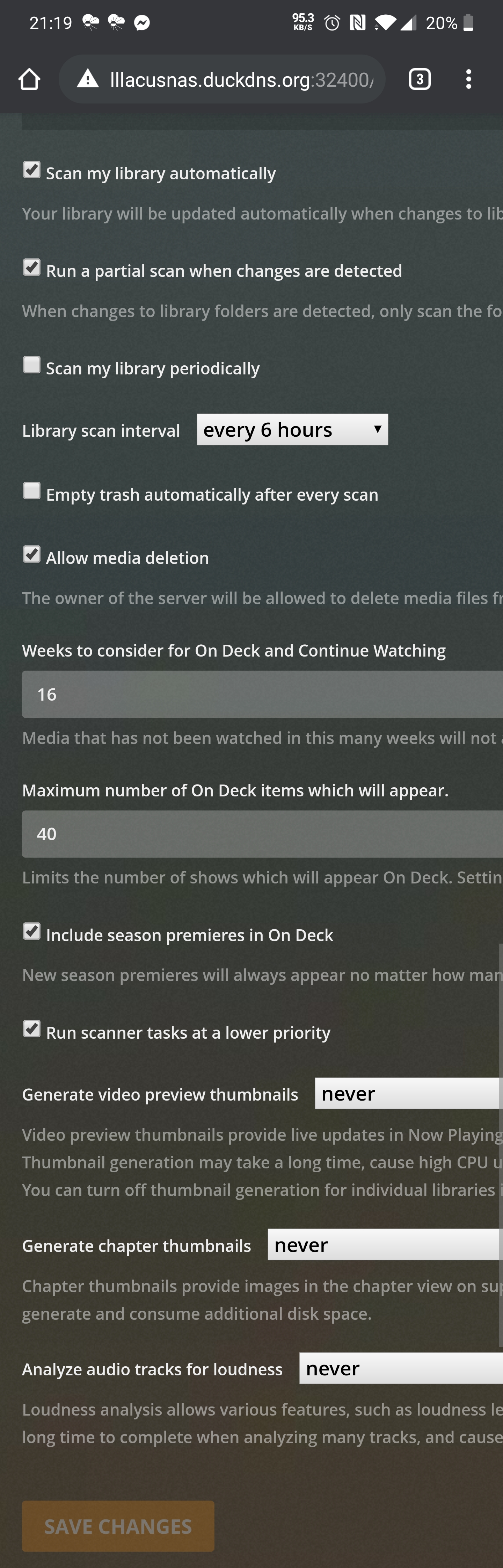
I can not comment on spesific settings inside Plex because I am not a regular user of it myself yet.
Other people here can surely help with that more than me.
But it is pretty hard in any case to read if you display it in your native language. If you want to get feedback on your settings via images you may want to consider switching the GUI to english temporarily when you take the screenshot.
As I said, I won't be able to help much in this regard, but there are plenty of other people here with plex experience.
As I said, I don't have the experience to say for sure - but based on what I know those settings look reasonable to me at least. It looks like you have disabled all of the really obvious problems (mostly periodic full metadata scans). Just keep an eye on your API graph if you feel like performance is suddenly bad. That will usually reveal any problems coming from settings.
Well you see here that you only peak at about 2 - 2,5 requests pr. second, so that is only a small part of your allowance. As long as it doesn't go very close to 10/sec then you don't have a problem with the API limit.
But you do have some issues there on "Errors by API method" that look like they are too high. When errors to go 100% rclone is struggling to do something because requests are erroring for some reason.
What method is the green and blue color? (scroll down to see)
Ah, well in that case it would be perfectly normal to see 100% error on drive.put type calls. Other operations should continue to work normally though. You will have to wait until tomorrow to upload more. The quota will reset sometime over night.
But otherwise you should not see may errors normally. 1-2% is ok and normal, but if you see much more you should try to see what is wrong. Seeing what type of operation fails is a very good clue to finding problems