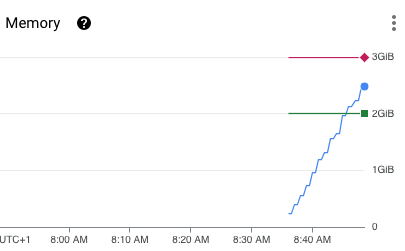
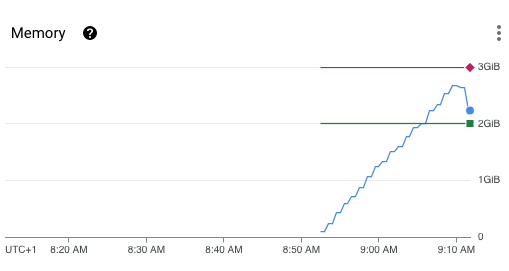
Can you try this, which loads all the objects into memory then prints some stats about them.
rclone test memory source:bigbucket/path/to/big/directory
With v1.61.1 and 1.59 - this will load all the objects into memory then show how much memory they use. If that particular directory won't load, choose a smaller one and run both versions on the same directory.
This will output something like this (I did a test on a local mino with 100,000 files in a directory)
$ rclone-v1.61.1 test memory TestS3MinioManual:rclone
2023/01/10 17:49:45 NOTICE: 100001 objects took 28694568 bytes, 286.9 bytes/object
2023/01/10 17:49:45 NOTICE: System memory changed from 53261576 to 107495704 bytes a change of 54234128 bytes
$ rclone-v1.59.0 test memory TestS3MinioManual:rclone
2023/01/10 17:50:09 NOTICE: 100001 objects took 363892552 bytes, 3638.9 bytes/object
2023/01/10 17:50:09 NOTICE: System memory changed from 49038344 to 546779256 bytes a change of 497740912 bytes
So in this test v1.60.1 is a clear winner by a factor of over 10.
It might be there is another problem which needs fixing which might be due to the exact format of your objects.
I first try on a relatively small directory (500k):
1.59.2:
./rclone-v1.59.2-osx-amd64/rclone test memory source:bucket/dirA
2023/01/11 07:53:36 NOTICE: 535994 objects took 1203576472 bytes, 2245.5 bytes/object
2023/01/11 07:53:36 NOTICE: System memory changed from 51135496 to 1781991048 bytes a change of 1730855552 bytes
1.61.1:
./rclone-v1.61.1-osx-amd64/rclone test memory source:bucket/dirA
2023/01/11 07:45:42 NOTICE: 535993 objects took 156525832 bytes, 292.0 bytes/object
2023/01/11 07:45:42 NOTICE: System memory changed from 55620872 to 358479176 bytes a change of 302858304 bytes
And I do have similar result as you.
Then I tried the "root" directory:
./rclone-v1.61.1-linux-amd64/rclone --config rclone.conf test memory source:bucket/
2023/01/11 14:12:39 NOTICE: 6898726 objects took 1919445272 bytes, 278.2 bytes/object
2023/01/11 14:12:39 NOTICE: System memory changed from 159567144 to 4169283320 bytes a change of 4009716176 bytes
The v1.59.2 did not complete due to not enough memory to fit in the VM I spawned (8Gb) so I would have likely get x10 also.
Although it make sense for rclone to build a sorted map of all the files within a directory for an efficient sync, in the context of the lsf (or similar) command where we just want to dump the list of files matching various conditions (dates, size, pattern, ...), requiring 4Gb of memory to list 6-7M of objects is just too much.
So it is not a bug, it works as designed, but it could perform way better in some scenarios I think.
I would like to fix this for all backends, but if you are using an s3 backend, when you do rclone lsf -R it should do exactly that - page through the list output and send it immediately to the output.
When I try this rclone lsf -R TestS3MinioManual:rclone > /dev/null rclone stays at a relatively constant 64M RSS over the 10s this takes.
I wonder whether there is something special about your rclone lsf
In practice between the output of rclone & the file I'm writing in I'm using awk to translate part of a path to something else and I have an awful feeling where it might buffer the whole output and if so I want to dig a hole and put myself in it.
But it's getting real late I'll try to test that hypothesis tomorrow, if yes, awefully sorry for the waste of time.
Specifically the filters that I'm using that are often things like:
siteA/
siteB/
Or:
2022-**
Those filters are flagged as Directory Filters and because of this rclone will use listRwalk instead of listR.
listR behave just like you said, and it starts to output the result straight away
listRwalk seems to load everything in memory first, or close to everything, and build a "synthetic dir summary" because listRwalk is run with ListAll even if lsf is run with --files-only (maybe because it needs directories infos to walk properly.)
Due to how S3 (and GCS) works (you have to paginate through everything), not sure if they are cases where listRwalk should be preferred, but I have a very narrow usage of rclone.
The reason rclone uses listRwalk rather than listR is to avoid the traversing the directories in your directory filters which it can only do with listRwalk (walking each path individually).
This is only a heuristic and if you were to comment out the fi.UsesDirectoryFilters() test then everything would still work. I guess we could put a flag in to force the ignoring of the directory filters. Though a) what to call it and b) how to document it so we remember what it does next week!
This change was done here
And was released in rclone v1.49.0 so its been in rclone a long time.
Rclone has two listing primitives in each backend ListR which has a nice callback interface using low memory to recursively list a directory and its contents and List which lists a whole directory and returns the whole thing at once.
I have a plan to convert List into a paged directory listing like ListR which would fix this problem and also enable on disk syncs for those S3 buckets directories with 100Million entries.
When doing anything which involves a directory listing (e.g. `sync`, `copy`, `ls` - in fact nearly every command),
rclone normally lists a directory and processes it before using more directory lists to process any subdirectories.
This can be parallelised and works very quickly using the least amount of memory.
However, some remotes have a way of listing all files beneath a directory in one (or a small number) of transactions.
These tend to be the bucket-based remotes (e.g. S3, B2, GCS, Swift).
Except the "use more memory" part for this specific use case.
Ok I tried commenting UseDirectionaryFilters and it works as I would have expected in my case.
But taking a step back and looking at the various cases I can have it's true that the correct behavior (walkR vs listR) is not clear cut, it really is on a per-case basis
For prefix-like backend (gcs, s3),
If filters look like:
2022-**
Then it would make sense to use listR approach since I'm bound to iterate through everything.
If the filters look like:
dirA/
dirB/
Then the best way would probably be to iterate within each directory in succession.
But at that point it could probably done by the caller of rclone like:
touch output.txt
for dir in [dirs]:
rclone lsf -R >> output.txt
Although it would be easier if rclone could be smart about this.
There no way to really know which strategy would be best in any case.
Yeah I think the best would be to have a flag to force the issue (like --fast-list where it depends on each case whether it's better or not).
And for filters that look like this (included folders only):
dirA/
dirB/
I could handle that in the application itself by calling rclone twice (dirA/ and dirB/) so that I can do 2 efficients listR and bypass the listing of other objects in the root bucket.
That's a hard one as it is kind of difficult as it is to understand how rclone behave (between heuristics such as this one, --no-traverse, --fast-list, ..).
Not even sure if "listR" or "walkR" appear under some name outside of the codebase or if this is a hidden implementation detail.
Not even sure whether the flag only impact "UseDirectionaryFilters" check or something along:
strategy = listR or walkR or undefined
if strategy is undefined:
strategy = resolveDefault()
if isListRSupported and strategy == listR:
doListR()
else:
doWalkR()
In that case it could be --recursion-strategy=walk|list|undefined?
ListR is mentioned in the docs, but it isn't well known.
Rclone changes which list method it uses depending on exactly what it is doing. For rclone sync and friends, rclone will use a plain List of each directory unless --fast-list is set, in which case rclone will use ListR if possible to load a complete object tree into memory.
For rclone lsf rclone will use List or if -R is supplied it will use ListR.
Not bad! A little generic though as this is specifically when we are using filters and recursive listing.
It would have the same function signature as the ListR backend method.
What I'm imagining is that we'd refactor existing List methods into optional ListP methods then provide a global function to adapt ListP to List. This would mean we don't have to re-write everything immediately.
We can then use the ListP interface if available in walk in place of List as this works with a callback interface already I think.
Alternatively the big bang approach would be to change the prototype of List. That would be a lot of work though as it would mean changing all 40 backends at once plus all the call sites.