I want to migrate data on my Google Drive's account to another drive, but the thing is that account recently had it's Drive API disabled and it's limited to it's organization, so the only way i can get the file to be migrated to another drive is by manually downloading the file while i'm logged into that account, otherwise i'd run into error 403 ( I even tried to share the file by link, it doesn't work too )
I did some research and found out that i can use "rclone copyurl" to download a file from an url to a drive, but when i use the download link that the site gave me, it'd redirect me the client to the login page. May i ask if it's possible to make rclone automatically fill in log in information on that page to reach the direct download link of that file? Thank you.
rclone copyurl expects the authentication to be working - it won't fill in a web form for you.
It might be that you could get the cookies out of a working download session with your browser and pass them into rclone copyurl using the --header flag.
I'm not sure how to do this, can you instruct it for me step by step, or link me any guide / instructions on how to get cookies out of a particular download session? Thanks!
Alright, i know which cookie works for the download now, but now i don't know how to input it into --header flag like you mentioned. It wants to take a string that looks like Content-Encoding: gzip. Do i have to make a file that contains cookie information and put inside the rclone folder?
Sorry if these questions caused you any inconveniences, i'm fairly new in this.
You want to add a flag which looks like --header "Cookie: COOKIECONTENTS" you can repeat that flag if you have more than one cookie (or other header) to add.
If i understand correctly, then what i need to add is--header "Cookie: COOKIENAME=COOKIECONTENT; COOKIENAME2=COOKIECONTENT2;..." ( Cookie - HTTP | MDN )
After i added the cookie as you instructed, rclone no longer downloads the login page, but it now starts getting redirected continuously and stopping download after it got redirected 10 times. This is the error that it's giving me now :
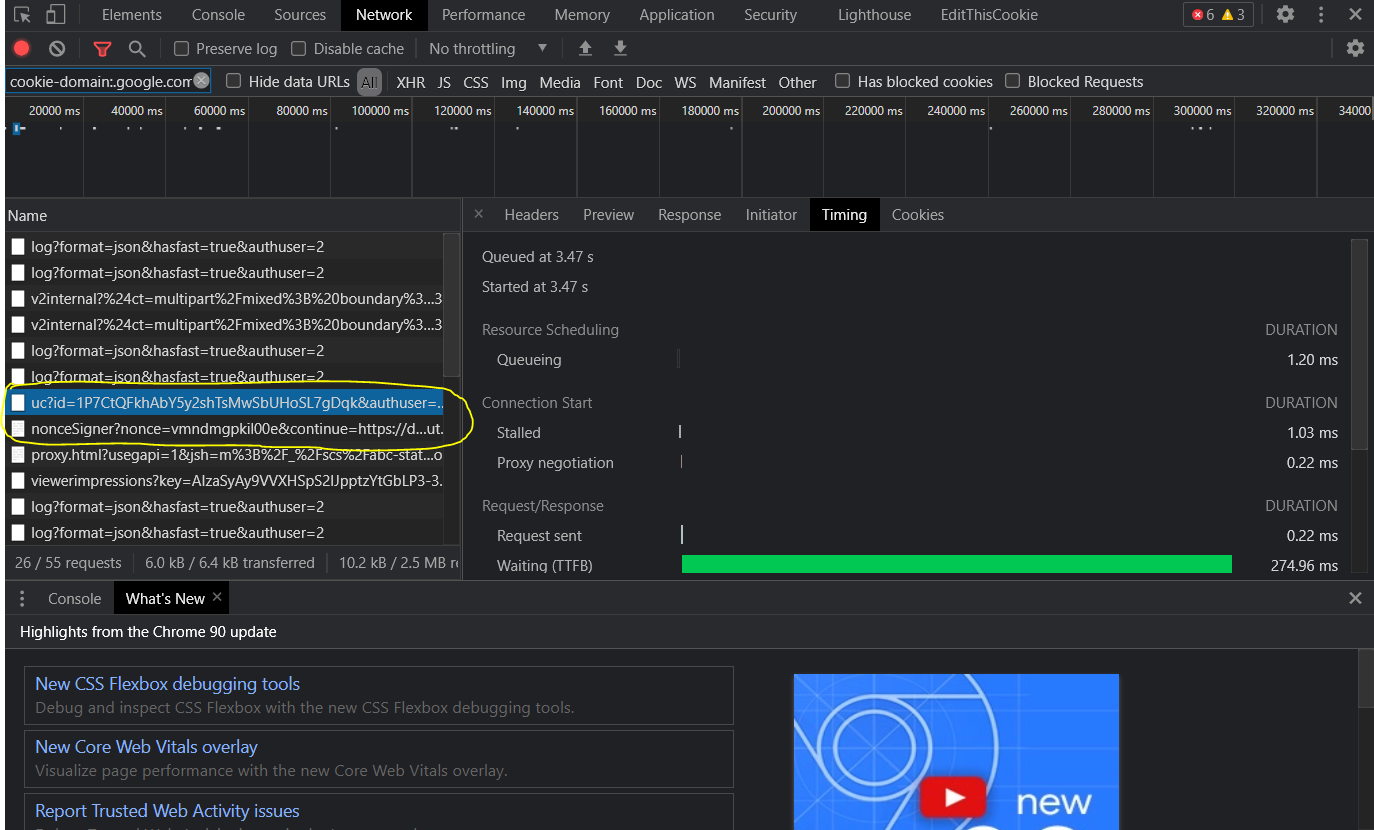
I've grabbed all the cookies that are displaying in the browser ( Totaling about 25 out of 34 that says "in use" in the browser. ). There are also things like "Shared Workers", "Session Storage", "Indexed Database", etc. like the ones in this picture, which they don't display any content and i don't know how to add them in as well as how important they are to the download.
Did that link come from the drive interface? How did you get it?
I logged onto my Drive account and download the file, then i cancelled the download, open the cookies and grab every cookies' names and contents. After i grabbed and put them into rclone behind --header, i click on the download button again to get a new link ( the old link would start giving 403 after 3-5 minutes ), then i paste the new link into rclone.
The google drive interface is a mass of javascript and I wouldn't be suprised if there were some more hoops to jump through other than just adding cookies.
If you use google chrome then you can find the transaction that downloaded the file and use save as curl - it would be worth trying to see if you can get curl to work.
I'm not sure what to do here, so i apologize and please bare with me if i did anything wrong here.
When i download the file, there are 2 requests popped up
1 after clicking to "Download anyway" button and before the browser receives the file download.
I copied the curl (cmd) of the latter one, removed all circumflexes, put them all into the same line, change -H into --header then proceed to place the download link and all the headers into the rclone copyurl command, the download still ended up being stopped after 10 redirects. I had to remove a proxy command and a header because i don't know how to put them in nor i think they were necessary, which are :
-X "POST" ^
-H "sec-ch-ua: ^\^" Not A;Brand^\^";v=^\^"99^\^", ^\^"Chromium^\^";v=^\^"90^\^", ^\^"Google Chrome^\^";v=^\^"90^\^"" ^
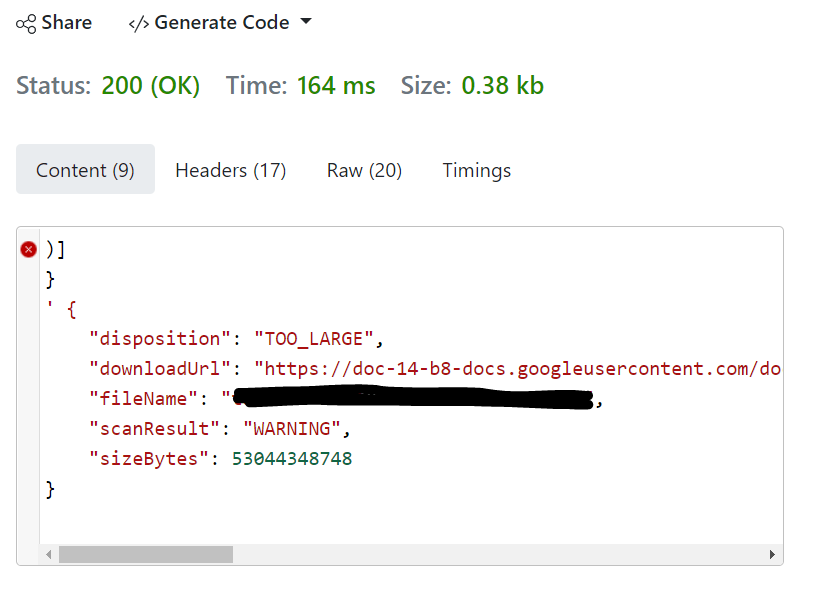
As for the first curl command, i ran it through an online tool which converts to HTTP request. The result returned with details of my file.
I figured it out! After i started downloading, i copied curl and modified all the header data so that it'd fit into rclone, then i download the file again so the link and the cookies get renewed because these two were the only things got changed between the downloads, then i copied the link in and changed header data of the cookie in the rclone command, and now it's working!