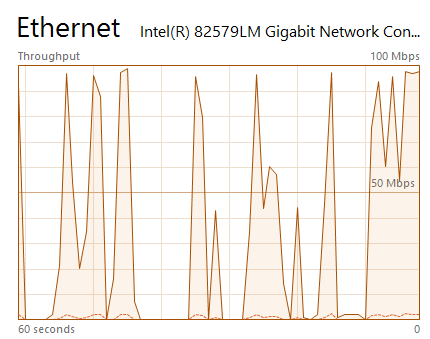
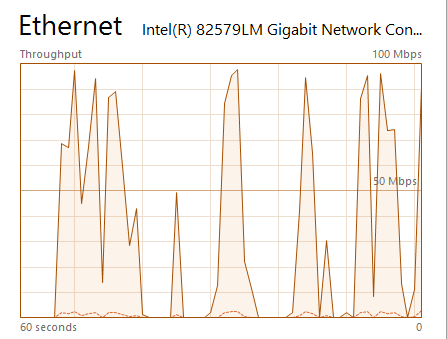
Is it possible to cache only the directory structure / filenames and not the file chunks? I’m trying to troubleshoot really bad cache performance (versus a non cache remote at the same provide) of file downloads. Basically the speed starts / completely stops / starts etc (as shown below). I’m wondering if this has something to do with slow disk performance so wanted to disable the chunks.
thanks, I will give that a go to see if it's disk performance. Do you know if it's possible to disable it completely? I'm happy to have the benefit of only fast directory listing (and fewer api calls) and not the cached files themselves.
Using that /dev/shm doesn’t seem to have made any difference.
Still very start / stop when using the cache. I’m giving up on it actually - using the cache is day and night slower when doing file transfers (download - upload via rclone still seems fine).
I’m on a slow server - atom processor, 2gb RAM so perhaps it’s performance related. Not sure why the cache would result in a bigger overhead though…
I’m not sure if I’m getting your use case. If you want to move files only, I’d definitely do rclone copy or move rather than doing a mount. The mount is a ton of overhead that’s not really needed if you are just moving files around.
If you want to play back or use them, I use the mount for plex to stream my files.
I have a rclone mount which is presented over nginx as a web directory. Those file downloads (through chrome or whatever) are as fast as the NIC on the server (100mb/s) through a standard gdrive -> crypt. They crawl when using gdrive -> cache -> crypt. I got the occasional ban, which is why I looked at cache.
Pretty sure my ban was too many API calls rather than too much b/w - kodi scanning the web directory as a video source. Am I correct in thinking that feature would reduce download volume rather than API calls?
The terminology is probably important as you normally don’t get banned per se for making API calls. You’ll get throttled and a bunch of 403s usually, which are rate limiting messages.
The issue before was that Plex/Emby/Kodi (to my knowledge) opens and closes file a lot to probe/analyze them. It would see that as a full download of the file each time so you’d get banned for downloading the same file multiple times per second.
I’ve been running the vfs-read-chunk-size now on and off for ~6-8 weeks I’d say. 2 days ago, I just rescanned an entire 45TB in plex in ~2.5 days with no bans, some 403s as Plex sometimes tries to open 40-50 files in a second, but overall, no issues.
The daily API limit is 1,000,000,000 calls. With all my shenanigans, I’ve only ever hit 140k calls in 30 days.
Awesome, sounds like I should give this a go then! I guess using tps limit would prevent those 403’s by sacrificing a little of the scanning speed.
-edit- have just changed over to this now. Performance looks great, and hopefully no bans. Looks like that dir cache option listed here New Feature: vfs-read-chunk-size actually was what I wanted in the first place. Seems to cache directories and nothing else, which is perfect.
@Animosity022 Re: that github issue you posted. If you don’t want chunks stored on disk, what’s the advantage of using the cache in the first place? If you just want the directories/files cached to avoid the bans then you can just use --dir-cache-time on a normal remote and do away with a cache remote entirely. This would keep the files in memory as they are transferred/streamed and not on disk.