Hey guys, I was wondering which are the best practices when it comes to folder and library organization to avoid excess API usage when using Drive, Plex and Rclone mount.
I'm thinking mostly of movies.
If I put all the movies in a main folder, updating the library usually goes past all the folders inside. Sometimes it insists in updating some older things in there.
I suppose Rclone eventually is making API calls and accessing data on the older files, which usually we don't want to touch.
I wonder, then, if making subfolders and libraries by year would be more efficient and would use less resources when updating your library, avoiding excess usage of API calls and unnecessary reading and writing on the Drive.
Or am I thinking too much and there's no difference? Let me know, what do you guys do?
Just some terminology, rclone really does not access anything, it's the applications that are on top of it that are hitting the data and they are requesting things.
When Plex lists out a directory and it has already analyzed the files and the directorry in rclone has not changed, it just gets a cached listed from rclone so no API call happens.
If the directory has a change, rclone will request a directory listing. Depending on how that's setup as I have all my Movies in a single folder, that call takes a bit longer as I have ~3k directories in the folder.
Efficiency for those operations can be helpful, but those API calls really do not matter much as you have quite the number of API calls per day.
I use Radarr which wants a folder for each movie currently so it's very inefficient in setup as I would normally try to keep a few hundred in a folder to speed things up. You can do that with multiple root directories in Radarr, but seems annoying to maintain. If they get the pull request for multiple files per folder, that would help out.
Same can be said for Sonarr as you can do the same here. Breaking things out into multiple root directories speeds up the cold scans and does help out.
If the path and file have not changed in Plex and the file has already been analyzed by Plex, it's just comparing the file attributes and does not access the file at all.
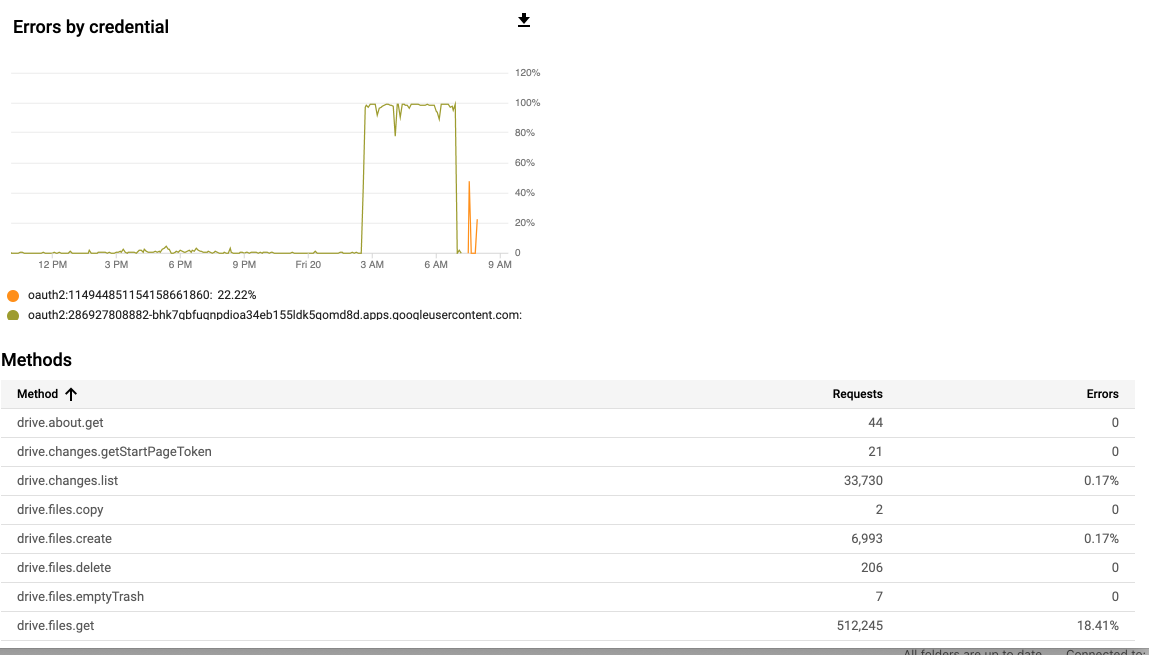
The only thing to worry about is there are 2 quotas, which are a download quota and upload quota per day. The upload quota is well documented and is currently 750GB per user. Once you hit this number, it returns 403 errors and does not let upload anymore and resets sometime over night for me (EST time zone).
The download quota is supposed to be 10TB per day but not documented anymore and no one is quote sure how that's calculated. I've done my own testing and the only way I can seem to break it and get a download quota error is generating ~500k drive.files.get in under a 24 hour period.
Once I did that, it stops me from downloading for that particular user on a drive. My normal use is roughly 40k gets per day, which is maybe 50-60 plays per day of TV Shows / Movies.
Using fewer folders or having most of your most-accessed files in one, or just a few folders could technically help with reducing the listing calls - as each folder with a file you are interacting it may need a listing.
That said, as Animosity points out you have lots of API calls to use. Probably more than you can use. The only real limit there is the 1000calls pr. 100 seconds which limits how bursty those calls can be, but rclone deals with this smoothly and just throttles down a little as needed if you suddenly burst a lot. Besides, most users will not reach the 10calls/sec average anyway.
So yes, you are probably overthinking it. You are probably better off basing your organization around other priorities.
Also, if you can use --fast-list this will ball together many list requests into a single call, thus greatly reducing API strain (and usually being much faster). Unfortunately it will not work through a mount (as the OS only knows to iterate through). Very useful for any sync-jobs or manual bulk-uploading though.