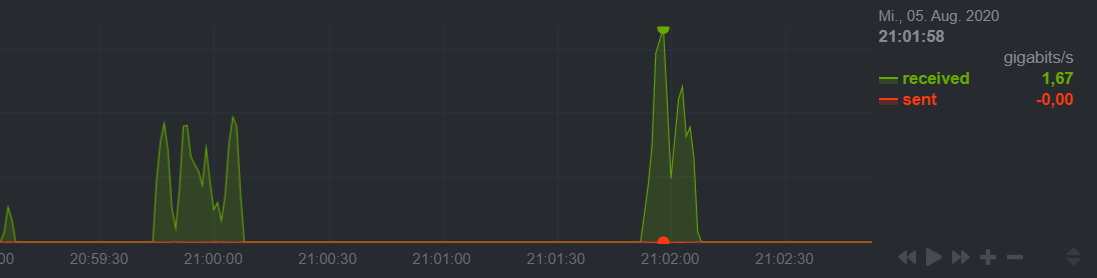
I've tested it sucessfully with default --buffer-size and --vfs-read-ahead 4G. Works great! Starts streaming fast as always AND it seems like the whole File (3,5 GB x265 Movie) is downloading via --vfs-read-ahead
--buffer-size
--vfs-read-ahead 4G
--vfs-read-ahead