Thanks Nick. You’re right - I can’t ping the docker from the server that’s running it. My plex docker is running in a VLAN and I’ve learnt that there’s some weird macvlan thing where dockers not in a vlan can’t communicate with dockers that are in a vlan, but I never imagined that applied to localhost as well.
Will investigate to see if I can fix. I’m hoping this might explain my slow media starts. Will share if I learn anything.
It sounds like the issue is that rclone is not running on the same network as the Plex server. Are they?
Later Edit: You already confirmed that it’s not. And yes, without talking to Plex cache will not increase its workers causing slow reads. I would disable the feature completely until the connectivity is restored.
With a few tweaks, I’ve got my launch times now down to around 10-12s on average which is acceptable for me as I know what’s going on behind the scenes - will keep an eye on the WAF! Everyone who’s getting faster speeds I think are using VPS
Adding --cache-chunk-no-memory (realised this keeps the chunks in memory and not caching them, rather than saying to not use memory - duh!) seems to have helped.
I played with smaller and larger chunk sizes, but they made 5M and 15,20M made things worse.
I bumped workers up to 50 when I read this was a ceiling, not the amount always used. I’ll increase dir-cache-time and --cache-info-age once my background rclone move job finishes moving content
rclone mount --allow-other --dir-cache-time=1h --cache-db-path=/tmp/rclone --cache-chunk-size=10M --cache-total-chunk-size=8G --cache-info-age=2h --cache-db-purge --cache-workers=50 --cache-chunk-no-memory --cache-tmp-upload-path /mnt/user/rclone_upload --cache-tmp-wait-time=60m --buffer-size 0M --log-level INFO gdrive_media: /mnt/disks/google_media
Note: If the optional Plex integration is enabled then this setting will adapt to the type of reading performed and the value specified here will be used as a maximum number of workers to use. Default: 4
If I’ve read this right if Plex is linked then this is a ceiling and i.e. is adaptive not fixed - hopefully I’ll only hit this on very rare occassions when there is high concurrent usage (not on my server) so it shouldn’t affect me
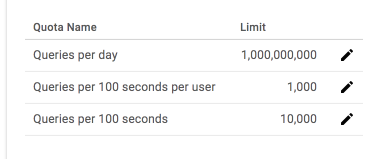
The quota for queries per second is 10 unless you’ve gotten insanely lucky and convinced Google to upgrade it.
If you have a 3 people playing movies and if it even upped to 10, you’d be pushing 30 per second as they run concurrently.
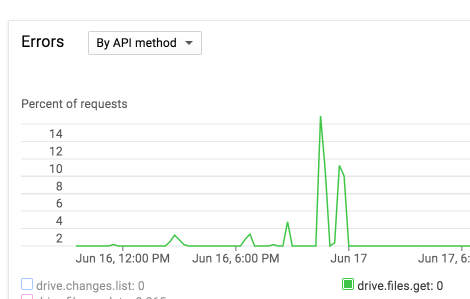
Example of the API errors when it’s high. I was on 8 during that test config and had a few test files going.
Also, if it’s too high, you’d end up waiting for worker 10 to give you a chunk back. It depends on your CPU/Internet/etc. There is a sweet spot of workers and your setup. Higher is not always better.