I was running some tests for non-rclone purposes and building and tearing down a lot of Plex servers. One of the most frustrating parts for a new Plex setup is that initial scan (yes, I know there are ways to copy this data from another, fully-populated server). Basically, Plex has to look into each file to find out more than just the filename so that it can identify other attributes and queue up downloading of artwork and so on.
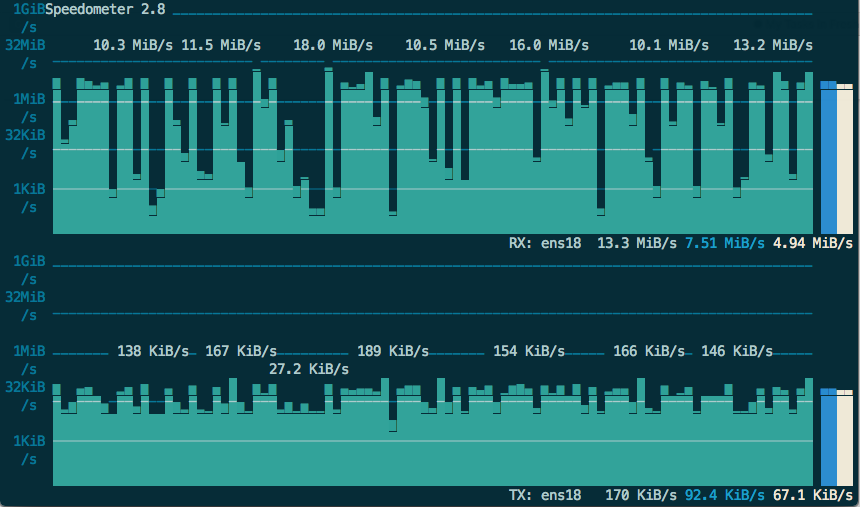
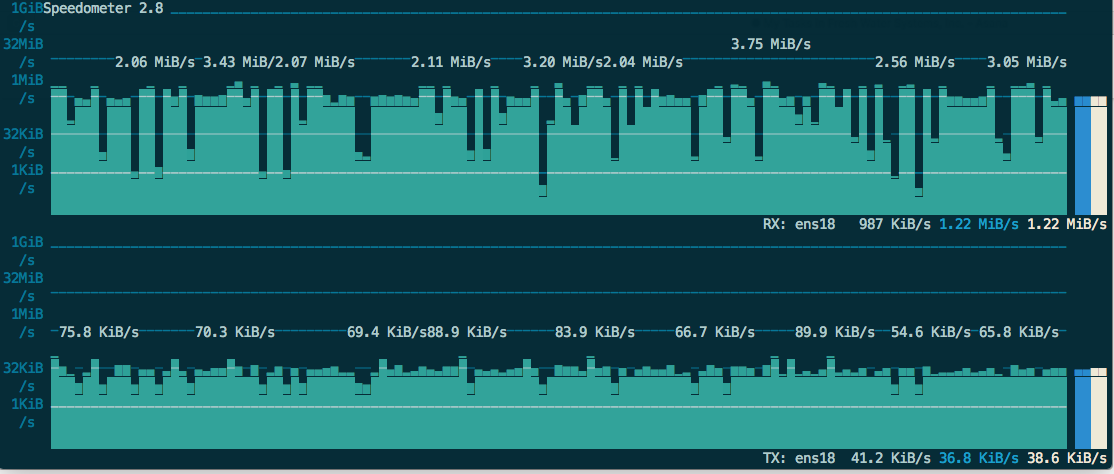
So I started thinking about it and realized that, with a chunk-size of 10M, for example, an rclone mount will have to grab the first 10M of each file as it is scanned (unless I’m mistaken). So, I dropped the chunk-size down to 1M and created a brand new server. That initial scan dropped from 1 hour to 45 minutes (25% speed increase) of my movies. [ Test with 500 movies on Google with Rclone Cache mount; time is measured from start of scan to the point where Plex shows a 500 movie count ]
Now, Plex still has to download the artwork and other elements but that’s outside of Rclone.
So, the question is: is it possible for rclone to “know” through Plex integration that Plex is scanning and, only then, bypass the set chunk size and instead grab a much smaller chunk since, theoretically, Plex is not going to look past that first chunk?
Alternatively, if it is impossible for rclone to know when Plex is scanning versus streaming, there could be an option so that the first chunk grabbed for any new retrieval would be smaller? For example, on a normal “grab” of a file (for copying, streaming, etc.), it might grab 10M + 10M + 10M + … EOF. Instead, though, it would grab 1M + 10M + 10M + … EOF.
While the difference between grabbing a 10M versus a 1M chunk is small, it adds up with things like scans of movies (or especially TV show episodes) so that small change over the course of 10,000+ videos adds up to noticeable speed improvement.