Aug 30 09:43:44 L1 rclone[811]: &{file.mkv (r)}: >Read: read=131072, err=<nil>
Aug 30 09:44:04 L1 rclone[19316]: Serving remote control on http://127.0.0.1:5572/
Aug 30 09:44:04 L1 rclone[19316]: Fatal error: Can not open: /mnt/remote: open /mnt/remote: transport endpoint is not connected
What is your rclone version (output from rclone version)
1.48
Which OS you are using and how many bits (eg Windows 7, 64 bit)
Ubuntu 18.04
Which cloud storage system are you using? (eg Google Drive)
Google Drive
The command you were trying to run (eg rclone copy /tmp remote:tmp)
rclone mount
A log from the command with the -vv flag (eg output from rclone -vv copy /tmp remote:tmp)
There are no logs it just start saying the transport endpoint is not connected, this have been stable for weeks and just because I removed 2 options people said had no effect on the mount and now is not stable anymore.
Like I said nothing, it was already running, then it stopped, then I assume the systemd tried to restart it and then it fails.
Now I somehow wiped the logs so can't help again. How'd you edit my systemd so it's logging everything possible to a file instead of syslog to see if this happen again?
It seems even stopping with service vfs stop fails with this weird error
Aug 30 15:29:36 L1 systemd[1]: Started Rclone VFS Mount.
Aug 30 15:49:15 L1 systemd[1]: Stopping Rclone VFS Mount...
Aug 30 15:49:15 L1 rclone[17883]: Fatal error: failed to umount FUSE fs: exit status 1: fusermount: entry for /mnt/remote not found in /etc/mtab
Aug 30 15:49:15 L1 systemd[1]: vfs.service: Main process exited, code=exited, status=1/FAILURE
Aug 30 15:49:15 L1 systemd[1]: vfs.service: Failed with result 'exit-code'.
Aug 30 15:49:15 L1 systemd[1]: Stopped Rclone VFS Mount.
I think such errors are usually related to previous mounts that have not been properly shut down - and this will make trouble for trying to re-mount.
On windows I think a simple restart will clear anything like this, but I'm not sure if they are persistent on Linux and may have to be manually shut down with the appropriate command.
From the docs:
When the program ends, either via Ctrl+C or receiving a SIGINT or SIGTERM signal, the mount is automatically stopped.
The umount operation can fail, for example when the mountpoint is busy. When that happens, it is the user’s responsibility to stop the mount manually with
# Linux
fusermount -u /path/to/local/mount
# OS X
umount /path/to/local/mount
I'm not a Linux guy, so that's about as much as I can contribute I think in terms of spesifics.
We need information to help troubleshoot and so far the only thing you've shared the mount didn't stop right:
Aug 30 15:29:36 L1 systemd[1]: Started Rclone VFS Mount.
Aug 30 15:49:15 L1 systemd[1]: Stopping Rclone VFS Mount...
Aug 30 15:49:15 L1 rclone[17883]: Fatal error: failed to umount FUSE fs: exit status 1: fusermount: entry for /mnt/remote not found in /etc/mtab
Aug 30 15:49:15 L1 systemd[1]: vfs.service: Main process exited, code=exited, status=1/FAILURE
Aug 30 15:49:15 L1 systemd[1]: vfs.service: Failed with result 'exit-code'.
Aug 30 15:49:15 L1 systemd[1]: Stopped Rclone VFS Mount.
This line here shows the mount stopping:
Aug 30 15:49:15 L1 systemd[1]: Stopping Rclone VFS Mount...
There was something that interacted with systemd to stop it.
We'd need to collect some logs or something to look at.
You can turn on some logging via:
--log-level INFO \
--log-file /opt/rclone/logs/rclone.log \
As I shared above. If there is some data to look at to help out, let me know as so far, all we have "it broke at sometime" with nothing to look at to help troubleshoot the issue.
And now I'm seeing huge spikes with almost no files open!
Max: 738.86 MBit/s
With only 46 files open, there's no way rclone will be able to handle 200 open files at this rate.
I thought this settings could help, since this seemed to happen only when I ran a script that created heavy load in the mount, but it's impossible to use them. I should use 0 for both again.
I need each open file to download at least > 3 Mbps to not have issues.
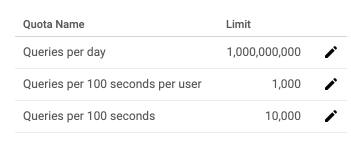
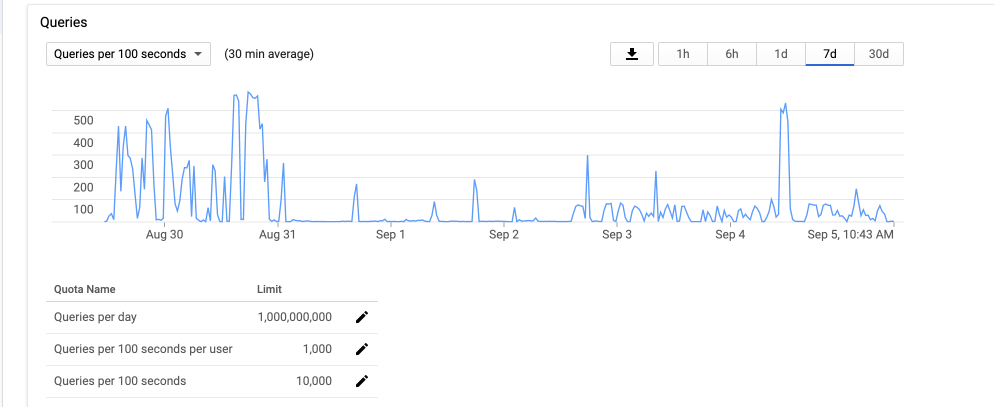
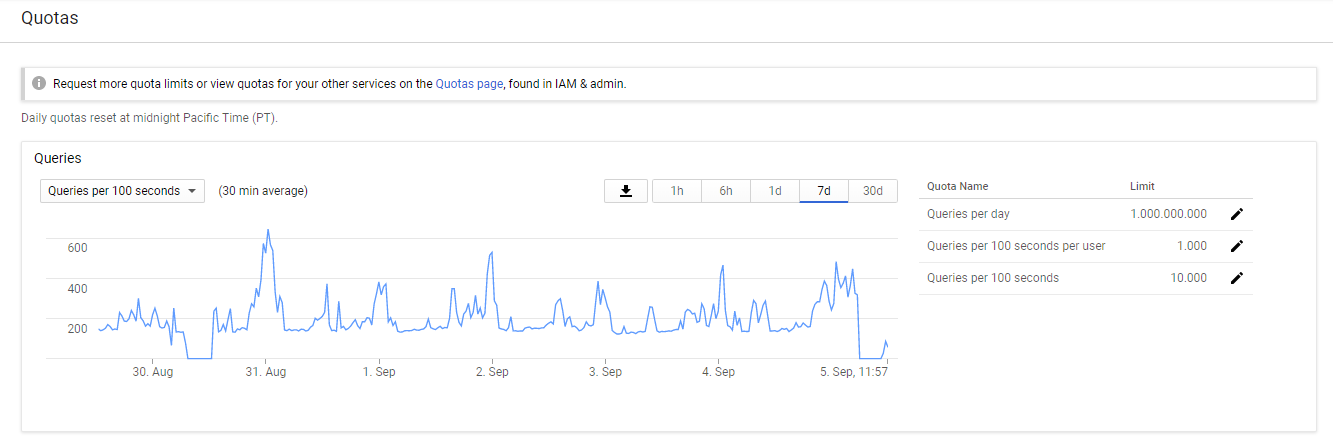
I think you need to probably take a step back and try to understand the limitations of the API and how you want to use it.
A single user can normally request 10 transactions per second roughly with the default quotas.
You are basically trying to fit the reading into that range and find the best use of the API limits that you have.
A single user streaming 200 files at the same time seems a bit much within the API. You'd probably want to request an increase of the API so you can deliver what's being requested.
I consume at times when I'm rescanning and doing a lot of imports, about half my 100 second quota. I normally have 6-8 streams going at max and that's easily under my quota as I use a the default range requests and it expands up based it sequentially asking for more of the file.
If that was the issue, that should appear on the logs too right?
nload stats of the server, with only 46 files open.
My server have 64 GB of ram, I'd never run out of memory, specially with my previous settings of 0 buffer size and 0 chunk-limit.
However I think I'll have to scale down the logging, with debug, with less than 1 hour is already at 50 MB... it will fill my disk before I can stress test the mount again
I'm a fan of plexdrive as I used that for quite some time and it's a great mount tool.
Trying to compare the two doesn't work though as they are very different in implementation and how to configure.
plexdrive is set to work with only Google Drive and has a use case of plex in mind and does very well in that use case. It doesn't allow deletes well and currently isn't really in development. For streaming, it really does it's thing well.
rclone works with a bazillion backends and has more configuration options than a swiss army knife for everything that it works with. It's really not quite as plug and play as plexdrive, which is both good and bad.
Over time, we've tried to tweak and tune defaults for the general use cases that people have by incorporating more of that in the defaults. It's not quite perfect, but it's a good start.
That being said, understanding why it drops would be key in if we found a new bug/defect or just a configuration needs to be tweaked.
I can't say I've ever had my rclone mount drop since I've been using it. My use case is very tuned/specific to me. I used to get plexdrive droppign here/there and would cron to check / restart it.
Everyone's use case/perspective is a bit different so I don't really rate one vs the other as they are both great and took someone's time to develop and share with other folks.
The reason I switched to rclone was to use service accounts and teamdrives, because I couldn't get my plexdrive to work with a teamdrive.
So I made my mount crash again, with debug logs enabled, and I see nothing, it's like rclone just dies without a reason and then we see my systemd restarting it and failing to do so (I don't know why either)
2019/09/06 13:38:05 DEBUG : &{24H/XXX/L/1/1.mkv (r)}: Read: len=131072, offset=2021851136
2019/09/06 13:38:05 DEBUG : &{24H/XXX/L/1/1.mkv (r)}: >Read: read=131072, err=<nil>
2019/09/06 13:38:05 DEBUG : &{24H/XXX/H/4/1.mkv (r)}: Read: len=131072, offset=92602368
2019/09/06 13:38:05 DEBUG : &{24H/XXX/H/4/1.mkv (r)}: >Read: read=131072, err=<nil>
2019/09/06 13:38:05 DEBUG : TV/Dragon Ball Z/Season 01/Dragon Ball Z - S01E01 - The New Threat [Bluray-1080p].mp4: ChunkedReader.Read at 185536512 length 8192 chunkOffset 185532416 chunkSize 10485760
2019/09/06 13:38:05 DEBUG : TV/Dragon Ball Z/Season 01/Dragon Ball Z - S01E01 - The New Threat [Bluray-1080p].mp4: ChunkedReader.Read at 185544704 length 16384 chunkOffset 185532416 chunkSize 10485760
2019/09/06 13:38:05 DEBUG : &{TV/Scooby-Doo, Where Are You!/Season 01/Scooby-Doo Where Are You! - S01E05 - Decoy For a Dognapper [WEBDL-1080p].mkv (r)}: Read: len=131072, offset=200867840
2019/09/06 13:38:05 DEBUG : &{TV/Scooby-Doo, Where Are You!/Season 01/Scooby-Doo Where Are You! - S01E05 - Decoy For a Dognapper [WEBDL-1080p].mkv (r)}: >Read: read=131072, err=<nil>
2019/09/06 13:38:05 DEBUG : TV/Dragon Ball Z/Season 01/Dragon Ball Z - S01E01 - The New Threat [Bluray-1080p].mp4: ChunkedReader.Read at 185561088 length 32768 chunkOffset 185532416 chunkSize 10485760
2019/09/06 13:38:05 DEBUG : TV/Dragon Ball Z/Season 01/Dragon Ball Z - S01E01 - The New Threat [Bluray-1080p].mp4: ChunkedReader.Read at 185593856 length 65536 chunkOffset 185532416 chunkSize 10485760
2019/09/06 13:38:05 DEBUG : TV/Dragon Ball Z/Season 01/Dragon Ball Z - S01E01 - The New Threat [Bluray-1080p].mp4: ChunkedReader.Read at 185659392 length 131072 chunkOffset 185532416 chunkSize 10485760
2019/09/06 13:38:20 DEBUG : rclone: Version "v1.47.0" starting with parameters ["/usr/bin/rclone" "mount" "--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36" "--config=/home/user/.config/rclone/rclone.conf" "--allow-other" "--rc" "--rc-addr=localhost:5572" "--drive-skip-gdocs" "--vfs-read-chunk-size=10M" "--vfs-read-chunk-size-limit=0M" "--buffer-size=10M" "--poll-interval=1m" "--no-modtime" "--dir-cache-time=24h" "--timeout=10m" "--drive-chunk-size=64M" "--umask=002" "--log-level" "DEBUG" "--log-file" "/opt/rclone/logs/rclone.log" "1:" "/mnt/remote"]
2019/09/06 13:38:20 NOTICE: Serving remote control on http://127.0.0.1:5572/
2019/09/06 13:38:20 DEBUG : Using config file from "/home/user/.config/rclone/rclone.conf"
2019/09/06 13:38:20 Fatal error: Can not open: /mnt/remote: open /mnt/remote: transport endpoint is not connected
Any ideas what could be happening?
It's not lack of enough memory since I have 48 GB in this machine.
That being said, your logs are somewhat strange too as rclone never crashes nor gets gracefully killed by a SIGTERM.
A normall "kill" gives you this output:
2019/09/06 11:34:05 DEBUG : rclone: Version "v1.49.1" finishing with parameters ["rclone" "mount" "gcrypt:" "/Test" "-vv"]
A kill -9 generates what you are seeing, which makes me think systemd is actually terminating the process on you and SIGKILLing it instead, which creates the exact error you are seeing in the logs with the mount being in use.
Pretty similar to this issue I saw earlier.
What does the systemctl status output show?
systeroot@gemini:~# systemctl status gmedia-rclone
● gmedia-rclone.service - RClone Service
Loaded: loaded (/etc/systemd/system/gmedia-rclone.service; enabled; vendor preset: enabled)
Active: active (running) since Fri 2019-09-06 07:26:20 EDT; 4h 10min ago
Main PID: 1178 (rclone)
Tasks: 22 (limit: 4915)
CGroup: /system.slice/gmedia-rclone.service
└─1178 /usr/bin/rclone mount gcrypt: /GD --allow-other --dir-cache-time 1000h --attr-timeout 1000h --log-level INFO --log-file /opt/rclone/logs/rclone.log --timeout 1h --umask 002 --user-agent an
Sep 06 07:26:19 gemini systemd[1]: Starting RClone Service...
Sep 06 07:26:20 gemini systemd[1]: Started RClone Service.