There is a concept in batch-processing known as pipe-size/commit-size/batch-reads and I was wondering if rclone uses such a concept under the hood.
The idea of batching is the services does many read calls and then one longer write(usually sequential write). In the case of networking it is equivalent to saying many read(byteArray, startPosition, length) and then one write call that writes the list of downloaded chunks.
If rclone uses such an idea is it configurable through the cli or config at all? What is the default value also?
Nothing is mounted, and the source is an HTTP server and the destination is the file system on my laptop. I currently have a bash script that runs runs a cron process that downloads the file periodically.
In this set up does rclone have a flag for this idea of pipe size?
Flags for parallelism yes, but I have not been able to find a flag for batching nor have I found any documentation that discusses this which is why I am curious if it is a hidden feature in the application.
There are various concepts like that in rclone but quite a lot of that sort of stuff is controlled by the Go runtime.
If you are using --multi-thread-streams then rclone will be writing at up to 10 different parts of the stream.
It will do this simultaneously - it doesn't buffer and write large chunks in each stream. This is a criticism others have made of the multi thread streaming as it fragments the underlying file more than it should.
I guess should start by saying I do not have any problems, all what I am trying to do is squeeze a little more performance out of RClone with my http downloads. From what I can tell RClone supports concurrency and parallelism for any protocol type that allows it already, so my intuition is that the only thing left would be to do some form of batching reading and writing. Hence my question which you have wonderfully answered my question .
One thing I have been googling around for regarding RClone is some form of a case study where an interpretation of thread values to impact on performance but I believe this is a lot to ask of an open source tool and if it does not yet exist I could potentially attempt at constructing one.
Good question I forgot to post my current set up.
I am currently allocating a 64 core HPC node that has a 10Gbps connection over ethernet to the public WAN. This server has NGINX running on it with ~100GB of data. It has an SSD and I will confirm the read and write speeds later by using DD.
The destination is a machine in another HPC site that is connected over WAN(< 500miles distance between the two) and has a link capacity of 10Gbps(here I will run RClone and write to disk which is also SSD).
What I am hoping is that RClone is able to hit around 7Gbps or greater for HTTP downloads. I will run the "copy" command and run with --multi-thread-streams=2^i and a --buffer-size=76M 76MB if I remember correctly is the avg Bandwidth delay product between the two sites that I have found in the past.
If the SSD speeds are under 10Gbps then I will set up the transfers to run as in memory copies to avoid the disk entirely and just copy the contents to disk post transfer with rclone as well.
Just to restate my expectation is to hit at least 7Gbps throughput for the entire transfer. I will post my findings once I graph everything which I expect to take at least a few days due to time constraints.
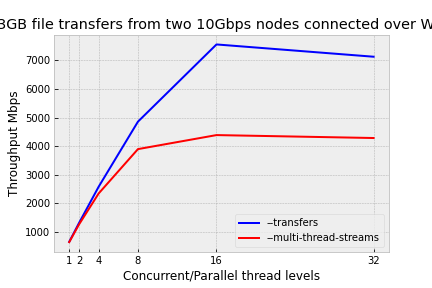
Hello everyone, I am very sorry for the delay(the HPC site I am using has been very booked up as of late and getting reservations has been difficult) but here are some preliminary results with RClone transferring ~128 GB over a WAN where on both ends of the transfer we have a 10Gbps link to the public net.
What I have not been able to reason is why the curve dips so intensely from 1 concurrency/parallelism to 2 and more generally why performance isn't doubling at the earlier levels(Amdahl's law at play?)?
My initial opinion is that this is simply the cost of having a critical section and the Go runtime doing some sort of locking?
A little benchmark details, there is a source server running NGINX (HTTP 1.1) where we are downloading a directories worth of files with a chunk size of 75MB. Now I will try lowering this chunk size to 20MB just to see if there is performance increase/decrease. Now I would like to add you see two plots b/c here I am comparing the throughput of measuring concurrency which is pinning the multi-threaded part to 1 and when measuring parallelism I am pinning the --transfers to 1.
Here is the command I am using from my bash script
Hmm, that is strange! Perhaps it is a cache effect with stuff running on two cores slowing things down? I suspect it is probably non-sequential disk IO that is the cause of the slowdown though - doing only one thing at a time will have perfectly sequential IO and file systems / disks tend to be optimized for that.
What is the destination file system? The performance of this will make a difference, especially for the --multi-thread-streams case where we will do a not of non sequential writing.
I read your comment last night and I made sure that the destination folder path was mounted as tmpfs, with this check it seems like that initial burst is gone from the graph :).
Here is my most updated graph.
One follow up question I have is, for Http downloads, when not using --transfers or --multi-threaded-streams is the file transfer still chunked or streamed? Also does RClone respect the --buffer-size flag when there is no concurrency or parallelism?
I have to say this tool is amazing, being able to hit 8 Gbps and move such vasts amount of data so consistently is very very impressive.